Implementasi Big Data Analytics Pada Grab
Grab selaku perusahaan startup yang bergerak di bidang transportasi menyediakan sebuah platform bagi pengemudi untuk dapat menawarkan jasanya dan pengguna untuk mendapatkan pengemudi untuk mengantarnya ke tempat tujuan dengan mudah. Perusahaan ini memiliki lebih dari 60.000 pengemudi yang terdaftar pada pertengahan tahun 2017 dan terus bertambah setiap harinya. Grab sendiri melayani di 7 negara di kawasan Asia Tenggara di lebih dari 40 kota (Grab, 2017). Dengan pengguna dan cangkupan layanan yang luas, perusahaan ini mengolah jutaan data setiap harinya. Lebih dari 500 ribu row data yang di update per jam dan lebih dari 50 juta insert per jam ke dalam database saat puncaknya dan hal ini terjadi setiap harinya.
Jumlah data yang banyak tentu membutuhkan analisa yang mendalam, sehingga dimulai dari tahun 2014, Grab mulai membuat data warehouse dan mulai melakukan eksplorasi terhadap tools untuk melakukan analytics. Perlu diketahui bahwa perusahaan ini memanfaatkan MySQL sebagai DatabaseManagement System mereka dan jumlah database yang digunakan mencapai 20 database. Pada rancangan awal, perusahaan ini memanfaatkan layanan Azkaban yang merupakan serviceopensource dari LinkedIn untuk mengambil data dari seluruh database setiap hari pada pukul 02.00 dini hari. Data ini kemudian akan di proses menggunakan Redshift untuk kemudian dilakukan proses (Extract, Transform, andLoad) ETL yang dapat memakan waktu hingga 2 jam.
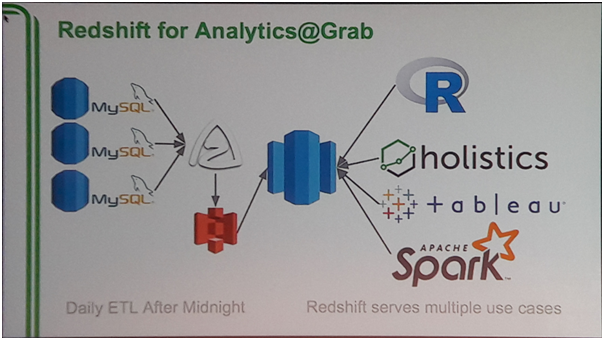
Gambar 1 Rancangan Data WarehouseGrab di Tahun 2014-2016
Setelah proses ETL selesai dilakukan, maka layanan lainnya untuk melakukan analytics seperti holistics, tableau dan Spark akan mengakses data yang ada pada data warehouse. Kendala yang dialami dengan menggunakan arsitektur seperti ini adalah data yang dianalisa tidak bersifat real time karena merupakan data kemarin dan beban pada Redshift sebagai data warehouse sangat tinggi seiring dengan banyaknya data analytics yang dibutuhkan. Pada tahun 2014 ini, Grab menyediakan sendiri infrastruktur dan server fisik untuk layanan Redshift yang digunakan.
Pada akhir tahun 2016, perusahaan ini mengambil keputusan untuk mengubah arsitektur yang telah ada dengan pertimbangan bahwa arsitektur yang lama tidak mampu menyediakan data analytics secara realtime dan implementasi server menjadi sulit mengingat permintaan yang banyak sehingga apabila server tersebut di upgrade akan membutuhkan biaya yang tidak sedikit.
Grab mengambil keputusan untuk memindahkan server ke layanan Cloud di Amazon dan berpindah untuk menggunakan Data Lake dengan memanfaatkan layanan Helios dari Amazon. Setiap databaseMySQL yang ada akan dikombinasikan dengan layanan PyroisOrchestrator yang akan secara otomatis melakukan ETL setiap jam dan data hasil ETL tersebut akan langsung disimpan ke dalam Data Lake. Di dalam Data Lake, data disimpan sebagai Parquet dan dipartisi berdasarkan waktu. Menurut Grab, partisi yang dilakukan harus sesuai dengan kebutuhan perusahaan, partisi berdasarkan waktu dianggap sesuai bagi Grab karena relevansi data yang paling dibutuhkan untuk dianalisa dalam perusahaan ini dibatasi oleh domain waktu.
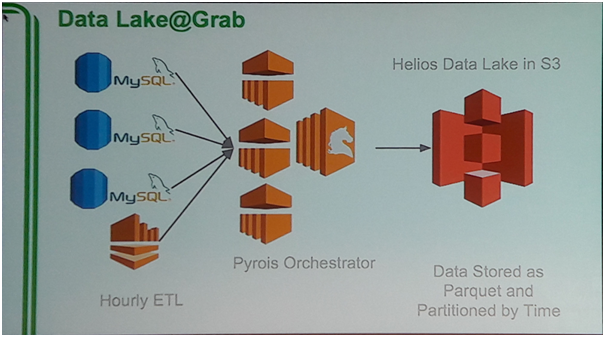
Gambar 2 Data Lake di Perusahaan Grab pada Tahun 2016
Perlu diingat bahwa layanan presto yang digunakan untuk analytics tidak mendukung otentikasi sehingga siapapun dengan akses ke jaringan perusahaan akan dapat melihat data analytics yang ada. Hal ini dinilai krusial dan perlu dibuat sebuah lapisan keamanan terhadap Data Lake yang ada. Oleh karena itu, Grab membuat sebuah Data Gateway yang diintegrasikan dengan otentikasi Google untuk membatasi akses kepada Data Lake yang ada. Dengan penambahan lapisan keamanan ini, Grab dapat membatasi orang yang dapat mengakses data dan membatasi akses dan query yang dilakukan.
Sebagai perencanaan untuk beberapa tahun ke depan, Grab ingin mengimplementasikan layanan Kafka dari Apache yang dikombinasikan dengan Spark yang juga dari Apache untuk mendukung streaming data secara real time. Kemudian hasil streaming ini dapat dimanfaatkan untuk juga membuat sebuah sistem real timemonitoring yang dinilai dapat membantu perusahaan mengambil keputusan dan mengerti sistem dengan lebih baik.
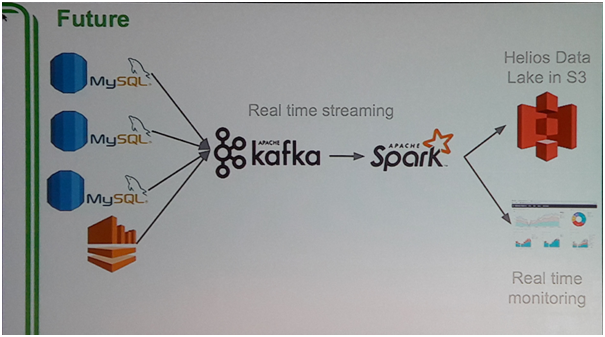
Gambar 3 Rancangan Arsitektur Data Lake Grab