TEXT ANALYTICS DI DATA WAREHOUSE
NANDA ADYTIANSYAH SILAOK07@GMAIL.COM
OEI KURNIAWAN UTOMO KURNIAWAN.UTOMO@OUTLOOK.COM
Dewasa ini perkembangan teknologi sangat pesat, termasuk teknologi data warehouse. Data
semakin bertambah jumlahnya dan segala jenis data yang kita butuhkan saat ini sudah hampir
semuanya tersedia di internet. Sebagaimana diketahui, Data Warehouse merupakan koleksi dari
informasi suatu perusahaan/organisasi dan data yang diperoleh dari operasional sistem dan sumber
data lainnya, dapat digunakan untuk mengambil keputusan sehingga memudahkan pengguna
untuk menganalisa seluruh data yang ada di dalam suatu database.
Text Analytics adalah metode dari Data Warehouse yang digunakan untuk memperoleh data
structured berkualitas tinggi dari kumpulan text unstructured. Nama lain dari text analytics adalah
text mining. Alasan menggunakan metode ini sebagai contoh adalah untuk mengekstrak data
tambahan dari sumber data yang tidak terstruktur ke master data yang besar untuk meningkatkan
wawasan atau untuk menjelaskan sentiment mengenai suatu produk dan layanan. Beberapa kasus
yang menggunakan text analytics sebagai berikut :
1. Case Management, contohnya klaim asuransi, medical record, dan investigasi criminal;
2. Analisis kompetitor;
3. Kesalahan manajemen dan optimasi layanan di lapangan;
4. Analisa hokum dari kasus litigasi;
5. Analisa media monitoring;
6. Uji coba farmasi;
7. Sentiment analytics;
8. Keluhan pelanggan.
Entity Extraction
Entity extraction merupakan penguraian dan ekstraksi dari teks yang masih mentah, merupkan
bagian penting dari text analytics. Contohnya sebagai berikut :
1. Nama perusahaan/organisasi;
2. Dates and Times;
3. Nama-nama yang spesifik seperti nama bagian dari tumbuh-tumbuhan;
4. Data moneter perekonomian;
5. Nama-nama orang beserta media sosialnya;
6. Sentiment, negates atau positif;
7. Nama-nama produk.
Di banyak kasus, entity extraction dapat dirubah menjadi automated entity recognition, dimana
teks diurai dan entities dipahami secara otomatis dipilih dari text yang ada dengan perangkat lunak.
Output dari text analysis terdiri dari text original dengan tambahan metadata dari text tersebut.
Intinya, banyak variasi dari berbagai aplikasi yang menggunakan banyak metadata, termasuk
aplikasi business intelligence, search applications, enterprise content management systems, dan
text mining applications.
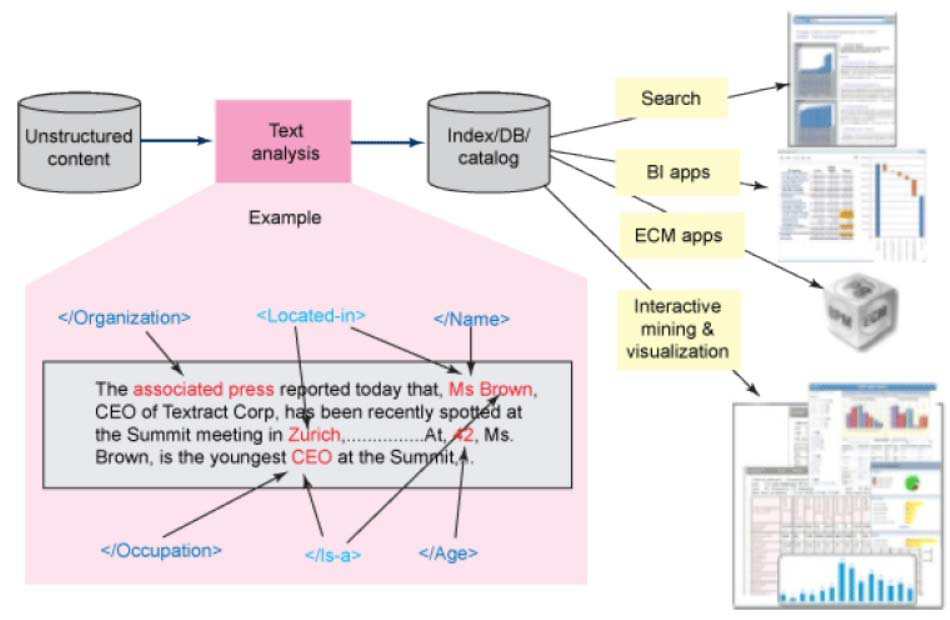 Gambar 1. Gambaran text analytics yang terdapat dibanyak aplikasi(https://www.ibm.com/developerworks/data/library/techarticle/dm-0804nicola/dm-0804nicola-pdf.pdf )
Gambar 1. Gambaran text analytics yang terdapat dibanyak aplikasi(https://www.ibm.com/developerworks/data/library/techarticle/dm-0804nicola/dm-0804nicola-pdf.pdf )
Sumber data yang dapat dianalisa oleh text analytics sangat besar dan luas, termasuk data-data
yang berada di dalam media sosial seperti Facebook, LinkedIn, Twitter, Instagram, dan juga isi
email, artikel berita, online discussion forum, review website (TripAdvisor), PDF documents,
online forms, serta catatan-catatan yang ada di dalam Customer Relationship Management (CRM).
Sebenarnya text analytics telah ada selama bertahan-tahun, namun teknologi untuk mengolah Big
Data baru berkembang beberapa tahun belakangan. Perkembangan data diberbagai perusahaan
juga sangatlah cepat dan harus selalu diolah agar menghasilkan informasi yang bermanfaat. Proses
well-understood di dalam text analytics yang berfungsi untuk mengurai informasi di dalam
kumpulan data, dijabarkan tahapannya sebagai berikut :
1. Mengekstrak data mentah;
2. Memecah text menjadi dua bentuk, yaitu kata dan frasa;
3. Mendeteksi batasan waktu;
4. Mendeteksi batasan kalimat;
5. Menandai bagian-bagian dari bahasa, contoh: kata kerja, kata sifat;
6. Mengidentifikasi nama-nama benda;
7. Mengurai, contohnya mengekstrak kata dan benda dari text yang ditandai;
8. Mengekstrak knowledge untuk mengerti konsep seperti luka disuatu kejadian;
Text analytics dapat dikombinasikan dengan model analisis yang lebih tinggi. Contohnya untuk
memprediksi sentiment positif atau negative terhadap suatu hal yang disukai/tidak sukai banyak
orang berdasarkan profil masing-masing orang tersebut. Kemudian juga dapat dikembangkan
dengan analisis grafik, lokasi manusia, tempat, aktivitas, dan segala sesuatu yang diekstrak dari
text menggunakan suatu alat. Dapat dimungkinkan bahwa salah satu bentuk terbesar dari text
analytics adalah sentiment analysist. Sentiment analysist adalah proses untuk mengidentifikasi
nilai sentiment dari suatu text. Sentiment analysist merupakan salah satu teknik yang digunakan di dalam text analytics
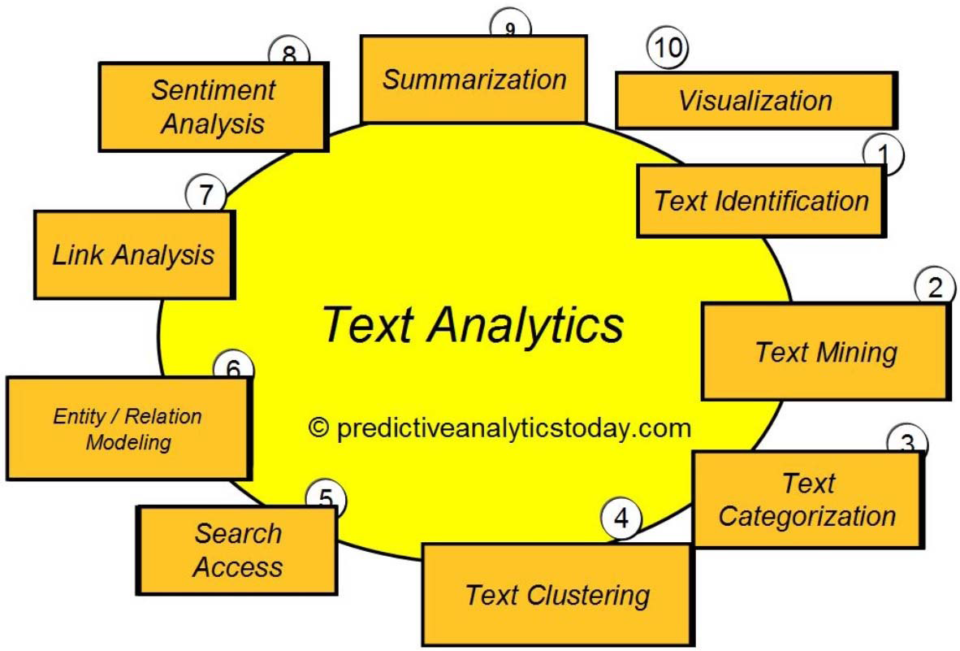
Gambar 2. Text Analytics process flow ( https://www.predictiveanalyticstoday.com/text-analytics/ )
Solusi yang ditawarkan oleh metode text analytics menyediakan banyak tools, servers, analisis
algoritma berbasis aplikasi, data mining, dan tools untuk mengekstrak informasi dari konversi
unstructured data untuk dapat di analisa.
Berikut beberapa aplikasi dari text analytics, sebagai berikut :
1. Sentiment analysist;
2. Akses pencarian data yang tidak terstruktur;
3. Email spam filter, untuk mengidentifikasi karakteristik pesan sehingga dapat mem-filter
advertisements, dan material-material yang tidak diinginkan seperti phising mail;
4. Automated ad placement;
5. Social media monitoring;
6. Kecerdasan kompetensi;
7. Business intelligence dan data mining;
8. E-Discovery, atau bisa juga manajemen pencatatan;
9. Keamanan nasional;
10. Penggalian ilmu pengetahuan;
Big data, Text Analytics, dan Predictive Analytics
Big data analytics, data mining, dan text analytics sepanjang berhubungan dengan statistik,
menghasilkan kemampuan pengguna bisnis untuk membuat predictive intelligence dengan pola
yang tidak terungkap dan saling berhubungan antara data yang terstruktur dan tidak terstruktur.
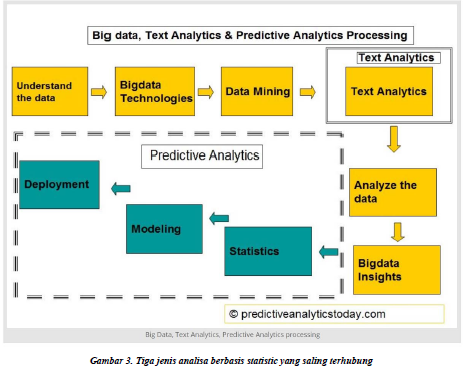
Gambar 3. Tiga jenis analisa berbasis statistic yang saling terhubung
( https://www.predictiveanalyticstoday.com/text-analytics/ )
Dengan Big data analytics, informasi relevan dari data warehouse yang berkapasitas terabytes,
petabytes, dan exabytes dapat diekstrak dan dianalisa untuk ditransformasikan menjadi keputusan
bisnis untuk masa depan.
Saat ini kita dapat menemukan text analytics yang tersedia di cloud, dan juga di Hadoop. Salah
satu modul yang ditawarkan IBM terkait text analytics adalah IBM BigInsight Data Science Modul.
Model ini termasuk tools berbasis web-based untuk mengekstrak informasi yang menghasilkan
sebuah bahasa yang disebut Annotation Query Language (AQL) untuk melakukan analisa. Modul
ini juga dapat mengkompilasi data secara cepat dengan sentiment analysist.
Kesimpulan
Text Analytics memiliki peranan penting dalam mengolah informasi untuk diproses agar
menghasilkan suatu keputusan berbasis sistem dengan menghapus batasan antara data yang
terstruktur dan data yang tidak terstruktur. Berdasarkan sifatnya, data yang tidak terstruktur sulit
untuk langsung diekstrak menjadi informasi yang bermakna dan dikombinasikan dengan data yang
terstruktur. Meskipun, struktur dan informasi semantik dapat ditambahkan ke data yang tidak
terstruktur melalui text tagging dan anotasi, cocok untuk diintegrasikan dengan berbagai sumber
data.
Sources :
1. https://www.techopedia.com/definition/1184/data-warehouse-dw
2. https://tdwi.org/articles/2017/04/10/evolving-the-data-warehouse.aspx
3. http://www.dataversity.net/data-warehouse-past-present/
4. https://www.ibm.com/developerworks/data/library/techarticle/dm-0804nicola/dm-
0804nicola-pdf.pdf
5. https://tdwi.org/articles/2007/05/09-what-works/bi-search-and-text-analytics.aspx
6. http://www.ibmbigdatahub.com/blog/what-text-analytics
7. https://www.predictiveanalyticstoday.com/text-analytics/