Optical Character Recognition (OCR) menggunakan Tesseract dan Penerapannya pada Industri Digital di Indonesia
Penulis: Kemal Anshari Elmizan, David Alfa Sunarna, Benni Bangun, Arya Dhanika
Pembimbing/Editor: Amalia Zahra, S.Kom., Ph.D.
Optical Character Recognition (OCR) adalah salah satu teknologi information retrieval yang berfungsi untuk mengekstrak informasi yang didapat dari gambar menjadi teks. Teknologi ini sering disebut juga text detection. OCR merupakan bagian dari teknik identifikasi otomatis. Terkadang cara tradisional untuk melakukan input data melalui keyboard bukan merupakan cara yang paling efisien. Dalam beberapa kasus, identifikasi otomatis dapat menjadi solusi.
Library open-source yang sering digunakan untuk teknologi OCR adalah Tesseract (https://github.com/tesseract-ocr/tesseract). Teknik character recognition dari Tesseract berawal dari riset engineer dari perusahaan Hewlett Packard (HP). Beberapa tahapan utama yang digunakan untuk OCR di Tesseract adalah line and word finding, word recognition, static character classifier, linguistic analysis dan adaptive classifier.
Line and Word Finding
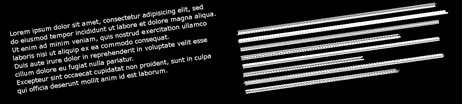
Gambar 1. Gambar awal dan hasil algoritma pencarian garis teks
Tahap pertama pada OCR adalah mencari garis teks menggunakan algoritma. Algoritma ini akan mencari objek serupa yang berada di dalam suatu garis. Objek tersebut kemungkinan akan berupa teks. Metode ini juga digunakan untuk menentukan kemiringan teks.
Setelah garis teks ditemukan, selanjutnya akan dibuat garis batas yang menentukan garis batas atas, garis tengah, dan garis bawah dari objek yang sudah diidentifikasi. Kemudian akan dideteksi jarak atau spasi antar huruf dan dilakukan pemotongan sehingga masing-masing huruf akan terpisah.
Word Recognition
Salah satu bagian proses dari mesin pengenal karakter (character recognition) adalah untuk mengidentifikasi bagaimana kata-kata bisa disegmentasi ke karakter. Pembagian awal sebagai output dari line finding diidentifikasi terlebih dahulu. Jika ada karakter-karakter yang tergabung karena adanya kerning, maka karakter-karakter tersebut dipotong terlebih dahulu dengan teknik chopping. Selain karakter-karakter yang tergabung, biasanya hasil dari tulisan banyak yang karakternya rusak karena hasil cetak yang terpisah-pisah. Hasil cetak yang terpisah-pisah digabungkan dengan teknik associating broken characters.
Static Character Classifier
Pada tahap ini, Tesseract menggunakan machine learning untuk mengidentifikasi huruf. Huruf mempunyai banyak variasi dari segi font, ukuran, dan attributes. Belum lagi ditambah kualitas gambar yang berbeda-beda. Maka dari itu diperlukan data training yang berisi kumpulan huruf dengan berbagai macam bentuk agar deteksi yang dihasilkan bisa lebih maksimal.
Linguistic Analysis
Tesseract pada dasarnya hanya memiliki sedikit kemampuan analisis linguistik. Kapan saja modul pengenalan kata menemukan segmentasi baru, modul linguistik akan memilih string kata yang terbaik melalui beberapa kategori. Segmentasi yang akan dipilih adalah yang mempunyai kata dengan total rating distance yang paling rendah, dengan kategori yang telah dikalkulasi dengan konstan tertentu.
Adaptive Classifier
Adaptive classifier lebih sensitif untuk font. Teknik ini menggunakan output dari static classifier (trained) yang digunakan untuk menghasilkan perbedaan yang besar untuk tiap dokumen yang mana jumlah font-nya terbatas. Tesseract tidak memiliki template untuk classifier, tetapi menggunakan feature dan classifier yang sama dengan static classifier. Perbedaan antara static dan adaptive classifier (terpisah dari datanya yang telah di-training) yaitu adaptive classifier menggunakan isotropic baseline/x-height normalisasi. Teknik ini memberi kemudahan dalam membedakan huruf besar dan kecil, juga meningkatkan immunity untuk noise specs. Selain itu menghilangkan font aspect ratio dan juga membuat pengenalan akan superscript dan sub menjadi lebih mudah.
Implementasi pada Industri Digital di Indonesia
Teknologi Tesseract dipasarkan oleh Google melalui produk cloud-nya yang bernama Google Vision. Di era cloud sekarang ini, penerapan OCR sudah diadopsi oleh beberapa perusahaan melalui Application Programming Interface (API). API tersebut nantinya bisa dimanfaatkan oleh aplikasi kita untuk mendeteksi teks yang ada pada gambar.
Teknologi OCR diimplementasikan di beberapa start-up sebagai alat untuk membantu proses registrasi dan Know Your Customer (KYC) dari pengguna. Proses registrasi yang membutuhkan KYC biasanya membutuhkan photo ID yang dikeluarkan oleh pemerintah seperti KTP dan SIM. Untuk pencocokan data, pada saat registrasi biasanya pengguna diminta untuk melakukan upload foto KTP atau SIM nya. Setelah itu data hasil proses OCR akan secara otomatis di-input sebagai data registrasi.
Referensi:
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/33418.pdf
https://stackoverflow.com/questions/15686149/extracting-lines-from-an-image-to-feed-to-ocr-tesseract
https://github.com/tesseract-ocr/tesseract