Enhancing SIFT-based Image Registration Performance by Building and Selecting Highly Discriminating Descriptors
Penulis : Tri Fennia Lesmana
Dosen Pembimbing: Gede Putra Kusuma, PhD
- PENDAHULUAN
Image registration merupakan proses untuk mendapatkan kesesuaian posisi yang benar dari beberapa gambar pada scene yang sama dengan berbagai kondisi berbeda. Kondisi yang berbeda dalam hal pengambilan gambar dapat berupa waktu pengambilan gambar, sudut pandang, alat pengambil gambar, atau intensitas cahaya. Beberapa contoh metode yang digunakan dalam image registration adalah scale invariant feature transform (SIFT), speed up robust feature (SURF), robust independent elementary features (BRIEF), dan oriented FAST rotated BRIEF (ORB).
Scale Invariant Feature Transform (SIFT) merupakan salah satu metode image registration yang populer dan sudah digunakan secara luas. SIFT mendeskripsikan sebuah gambar dengan menemukan titik-titik (disebut juga keypoint) yang menonjol dari gambar. Dari setiap keypoint tersebut bisa didapatkan gradient orientation dan gradient magnitude yang diolah lebih lanjut untuk menjadi fitur dari keypoint. Selanjutnya, akan dibangun histogram dari gradient magnitude berdasarkan gradient orientation yang terkait, bin pada histogram akan memiliki rentang 0°, 45°, 90°, 135°, …, 315°. Selain gradient magnitude (GM) dan gradient orientation, terdapat juga gradient occurrence (GO) yang dapat dipertimbangkan untuk digunakan dalam image registration.
Berdasarkan penelitian yang telah dilakukan sebelumnya (Teng, Hossain, & Lu, 2015), terdapat masalah pada versi orisinil SIFT yang disebut gradient reversal. Masalah tersebut muncul jika terdapat dua sudut yang berlawanan dan memiliki nilai arctan yang sama untuk dua sudut yang berbeda, misalnya 30° dan 210°. Hal ini tentu dapat mempengaruhi hasil feature dimana tingkat diskriminatifnya menjadi sangat rendah.
Pada penelitian lain (Chen & Tian, 2009), telah dicoba untuk mengatasi masalah ini. Pertama, sudut pada gradient orientation akan dibatasi hanya 0° sampai 180° saja, tidak lagi 0° sampai 360°. Kedua, akan dibangun dua buah image descriptor yaitu gambar asli, dan gambar yang dirotasi sebanyak 180°. Ketiga, kedua image descriptor tersebut akan digabungkan. Metode ini dinamakan S-SIFT (Symmetric SIFT). S-SIFT mampu mengatasi permasalahan gradient reversal. Namun, penggabungan kedua image descriptor membuat S-SIFT memiliki kemampuan diskriminatif yang lebih rendah dan ambigu.
Untuk mengatasi permasalahan pada S-SIFT, kemudian metode ini diperbaiki lagi (Teng, Hossain, & Lu, 2015). Pertama, S-SIFT dilakukan untuk mendapatkan pasangan keypoint dari dua buah gambar. Kedua, selisih rotasi antara gambar referensi dengan gambar target di estimasi dengan menghitung rata-rata dari selisih antara orientasi utama dari setiap keypoint yang berpasangan. Ketiga, descriptor dibangun lagi pada gambar referensi dan gamber target seperti yang dilakukan pada S-SIFT. Teknik ini dinamakan IS-SIFT (Improved Symmetric SIFT).
Penelitian yang dilakukan (Teng, Hossain, & Lu, 2015) tidak menggunakan GM sebagai penambahan nilai pada bin histogram, namun yang digunakan adalah GO. Berikut gambar ilustrasi untuk menjelaskan perbedaan antara GM dan GO.

Seperti yang terlihat pada gambar, semua piksel diasumsikan memiliki gradient orientation sebesar 45°. Angka pada panah berwarna hitam menunjukkan nilai dari gradient magnitude. Satu bulatan merah menandakan satu buah piksel. Jika menggunakan GM, maka nilai untuk histogram pada rentang 45° adalah 36. Jika menggunakan GO, maka nilai untuk histogram pada rentang 45° adalah 6 karena keenam piksel memiliki gradient orientation 45°. Bagaimanapun juga, jika SIFT hanya menggunakan salah satu dari GO atau GM saja, hasil deskripsi akan memiliki keterbatasan dalam membedakan konten dari gambar. Pada penelitian yang dilakukan oleh (Lv, Teng, & Lu, 2016), akan dibagun metode SIFT yang baru, yang menggabungkan GO dan GM.
- TINJAUAN PUSTAKA
- SIFT (Scale-Invariant Feature Transform)
SIFT merupakan metode untuk menghasilkan fitur-fitur pada gambar yang memiliki sifat invarian terhadap perbedaan pada gambar seperti translasi, perubahan ukuran, rotasi, iluminasi, dan proyeksi 3 dimensi (Lowe, 1999). Berikut langkah-langkah untuk menghasilkan fitur SIFT:
- Constructing a scale space
Tahap pertama, dilakukan blur filtering pada gambar input dengan contoh hasil berikut:
(http://www.aishack.in/tutorials/sift-scale-invariant-feature-transform-scale-space/)
Gambar yang dihasilkan berjumlah sebanyak octave * scale. Pada gambar, octave ditunjukkan dengan ukuran gambar yang berbeda (menyamping) dan scale ditunjukkan dengan tingkat blur yang berbeda pada satu octave/satu ukuran gambar yang sama (ke bawah). Penulis paper menyatakan bahwa nilai octave dan scale yang ideal adalah 4 dan 5. Pada gambar, jumlah octave adalah 4 dan jumlah scale adalah 5 (pada octave pertama gambar terpotong, seharusnya terdiri dari 5 scale). Untuk octave pertama, gambar akan di perbesar dua kali lipat.
Operasi persamaan blur dapat dilakukan pada persamaan berikut:
![]()
Dimana:
- L adalah gambar hasil filtering
- G adalah operator Gaussian Blur
- I adalah gambar input
- X dan y adalah koordinat lokasi piksel
- σ adalah parameter “scale”
- * adalah operasi konvolusi
Operator Gaussian Blur: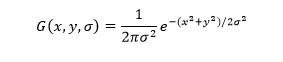 2. Berikut adalah contoh parameter σ yang digunakan:
2. Berikut adalah contoh parameter σ yang digunakan: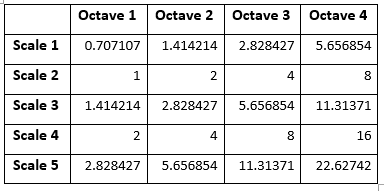 LoG Approximation
LoG Approximation
Dikarenakan komputasi yang berat jika menggunakan Laplacian of Gaussian (LoG), maka sebagai alternatif akan digunakan Difference of Gaussian (DoG). Pada DoG, dua scale yang berurutan akan dihitung selisihnya, berikut gambar ilustrasi:
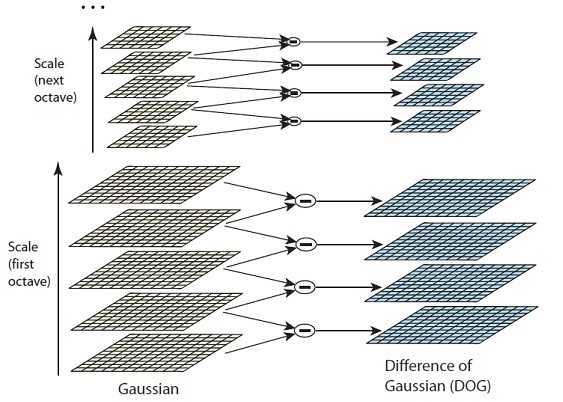 3. Finding keypoints
3. Finding keypoints
Pada tahap awal, dilakukan pencarian lokasi maksimal/minimal pada gambar DoG, berikut adalah gambar ilustrasinya:
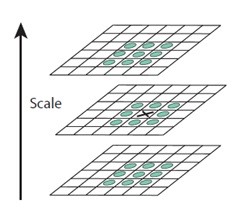
(http://www.aishack.in/tutorials/sift-scale-invariant-feature-transform-keypoints/)
Seluruh piksel pada gambar akan dicek dengan tetangganya. Sebagai penanda, simbol X menandakan piksel saat ini dan bulatan hijau adalah tetangganya yang terdiri dari 26 piksel (baik tetangga dalam scale yang sama, maupun tetangga pada scale sebelum dan sesudahnya). X akan ditandai sebagai aproksimasi “key point” jika X memiliki nilai terbesar atau terkecil dibandingkan dengan ke-26 tetangganya. Karena keypoint tersebut masih berupa aproksimasi dan bukan nilai pasti, maka selanjutnya di cari lokasi subpiksel.
Langkah selanjutnya adalah mendapatkan subpiksel maksimal/minimal. Dari keypoint yang sudah didapatkan pada langkah sebelumnya, posisi subpiksel akan dihasilkan berdasarkan persamaan berikut:
 4. Get rid of bad key points
4. Get rid of bad key points
Untuk menghilangkan fitur yang memiliki kontras yang lemah, dapat dilakukan dengan cara thresholding. Jika intensitasnya kurang dari nilai threshold, maka keypoint tersebut dapat dihilangkan. Selain cara tersebut, dapat juga dilakukan penghilangan non-corner keypoint karena corner merupakan keypoint yang bagus. Pendeteksian corner keypoint dapat dilakukan dengan menggunakan pendekatan Hessian Matrix.
Assigning an orientation to the keypoints
Tahap selanjutnya adalah menentukan orientasi dari setiap keypoint. Tahap ini membuat SIFT invarian terhadap rotasi. Gradient magnitude dan orientasi dihitung dengan menggunakan rumus berikut:
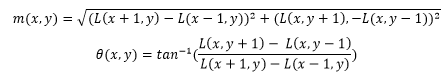
Setelah itu, orientasi sebanyak 360 derajat akan dibagi menjadi 36 bin. Setiap bin yang berada pada posisi diatas 80% dari bin tertinggi, akan diubah menjadi keypoint baru. Sehingga, dari tahap ini, satu keypoint bisa dipisahkan menjadi keypoint baru.
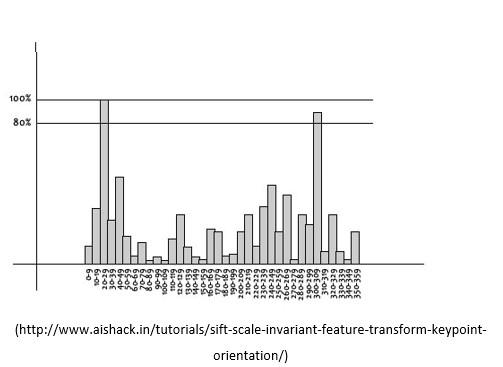
(http://www.aishack.in/tutorials/sift-scale-invariant-feature-transform-keypoint-orientation/)
- Generate SIFT features
Untuk setiap keypoint, dilakukan hal berikut:

(http://www.aishack.in/tutorials/sift-scale-invariant-feature-transform-features/)
Diambil 16×16 piksel matrix yang mengelilingi keypoint yang bersangkutan. Kemudian akan dipecah menjadi 16 buah matrix yang berukuran 4×4. Dari masing-masing matrix berukuran 4×4 tersebut, kemudian dibangun histogram yang memiliki 8 bin (rentangan 0-44, 45-89, dan seterusnya).
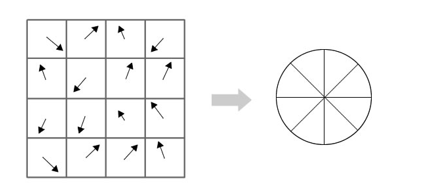
http://www.aishack.in/tutorials/sift-scale-invariant-feature-transform-features/)
Dari satu buah keypoint tersebut memiliki ukuran 16×16 dimana untuk 4×4 matrix memiliki ukuran 8 bin histogram. Sehingga, jumlah feature yang dimiliki adalah 8×16 = 128. Selanjutnya angka-angka tersebut dapat dinormalisasi untuk diproses lebih lanjut.
- Nearest Neighbor Distance Ratio (NNDR)
Feature matching adalah proses untuk mencocokan suatu keypoint pada suatu gambar dengan keypoint lain pada gambar yang lain. NNDR merupakan salah satu metode untuk melakukan feature matching. NNDR diawali dengan menghitung derajat persamaan antara fitur sebuah keypoint pada gambar 1 dengan seluruh keypoint yang ada pada gambar 2 dengan menggunakan Euclidean distance:
![]()
Dua keypoint pada gambar kedua dengan jarak terkecil diambil dan didapatkan rasio dari keypoint terdekat dengan keypoint terdekat kedua. Semakin kecil nilai rasionya, maka semakin besar kemungkinan kedua keypoint tersebut merupakan pasangan yang tepat.

(https://www.cse.buffalo.edu/courses/cse668/peter/pres/WZhu.pdf)
- Pengukuran Performa
Performa dievaluasi berdasarkan akurasi yang diberikan dari metode tersebut. Cara menghitung akurasi:
 3. PEMBAHASAN
3. PEMBAHASAN
a. Gradient Magnitude sebagai penambahan nilai bin pada histogram
Ketika hanya gradient magnitude yang digunakan sebagai penambahan nilai bin pada histogram, maka berlaku persamaan berikut:
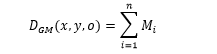
Dimana 1 ≤ x ≤ 4 dan 1 ≤ y ≤ 4, adalah nilai GM pada orientasi bin ke o, n adalah jumlah piksel yang masuk kedalam perhitungan histogram, dan adalah gradient magnitude pada piksel ke i.

Kelemahan jika hanya menggunakan gradient magnitude terlihat pada gambar. Pada gambar a, b, c, dan d, diasumsikan bahwa setiap panah memiliki gradient magnitude 45°. Jika dihitung histogramnya, maka keempat gambar tersebut memiliki nilai yang sama, yaitu 4. Hal ini menunjukkan bahwa gambar dengan konten yang berbeda bisa memiliki nilai deskripsi yang sama jika hanya dengan mengandalkan nilai GM. Tentu saja tingkat diskriminatifnya rendah.
b. Gradient Occurrence sebagai penambahan nilai bin pada histogram
Ketika hanya gradient occurence yang digunakan sebagai penambahan nilai bin pada histogram, terdapat fungsi sebagai berikut:

Kelemahan jika hanya menggunakan GO sebagai image descriptor terlihat pada gambar. Gambar a, b, c, dan d akan memiliki nilai 2 untuk orientasi tersebut. Padahal, jelas keempat gambar tersebut memiliki konten gambar yang berbeda. Hal ini juga dapat mengurangi tingkat diskriminatif dari SIFT.
c. Magnitude and Occurrences of Gradient pada SIFT (MOG-SIFT)
Sebuah pasangan keypoint yang memenuhi kriteria dari descriptor berbasis GM dan GO berpeluang besar untuk menjadi pasangan yang tepat dibandingkan dengan hanya mengandalkan salah satu dari GM atau GO. Image descriptor gabungan dengan menggunakan GM dan GO disebut dengan MOG-SIFT dan MOG-IS-SIFT. Tahapan dalam MOG-IS-SIFT adalah:
 d. Pemilihan pasangan keypoint dengan menggunakan Higher Discrimination (HD)
d. Pemilihan pasangan keypoint dengan menggunakan Higher Discrimination (HD)
Pada penelitian yang dilakukan oleh (Lv, Teng, & Lu, 2016) juga diusulkan metode HD untuk memilih pasangan untuk keypoint. Berikut langkah-langkahnya:
- Pembobotan rasio jarak
Rasio jarak pada pasangan keypoint yang dihasilkan dari IS-SIFT dan GO-IS-SIFT masing-masing dilambangkan dengan dan . Bobot rasio jarak DR, untuk setiap pasangan keypoint adalah:

 e. Uji coba metode yang diusulkan
e. Uji coba metode yang diusulkan
Uji coba dilakukan sebanyak dua jenis, yaitu untuk gambar multimodal (gambar memiliki brightness dan contrast yang berbeda dan ditangkap dengan alat yang berbeda) dan gambar monomodal (gambar memiliki brightness dan contrast yang mirip dan ditangkap dengan alat yang sama).
- Alasan memberikan pembobotan secara adaptif
Setelah dilakukan percobaan HD-MOG-SIFT dengan berbagai nilai α, hasil akurasinya adalah sebagai berikut:
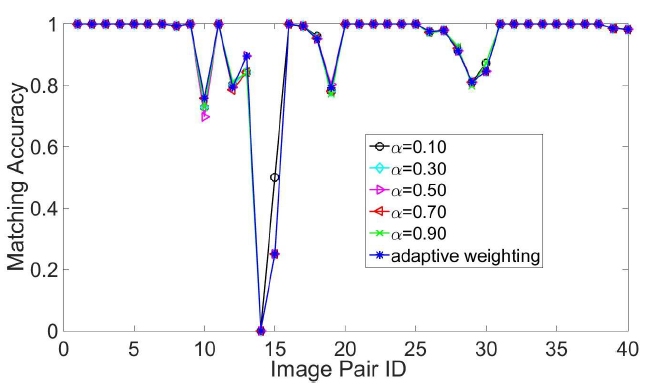
Berdasarkan hasilnya, jika menggunakan beberapa nilai α perbedaan akurasinya tidak terlalu jauh berbeda. Namun, hasil akurasi sedikit lebih tinggi pada beberapa kasus jika menggunakan nilai α secara adaptif. Maka dari itu, ditentukan nilai α secara adaptif daripada harus ditentukan secara manual.
- Dataset gambar monomodal
Dalam pengujian gambar monomodal, dataset yang digunakan adalah Affine Covariant Regions dataset dari http://www.robots.ox.ac.uk/~vgg/data/data-aff.html. Dataset ini terdiri dari 40 pasang gambar.
Metode yang diuji pada gambar monomodal adalah SIFT, GO-SIFT, MOG-SIFT, HD-SIFT, HD-GO-SIFT, dan HD-MOG-SIFT. Berdasarkan hasil, GO-SIFT selalu memiliki akurasi yang lebih baik daripada SIFT. Namun, GO-SIFT dan SIFT terlihat memiliki akurasi yang paling rendah pada hampir semua kasus jika dibandingkan dengan metode lain. Rata-rata akurasi untuk SIFT, GO-SIFT, MOG-SIFT, HD-SIFT, HD-GO, SIFT, dan HD-MOG-SIFT masing-masing adalah 77%, 81.88%, 87.76%, 89.19%, 90.28%, and 92.28%.

- Dataset gambar multimodal
Dalam pengujian gambar multimodal, terdapat dua buah dataset yang digunakan. Dataset pertama terdiri dari 18 pasang gambar NIR (Near-Infra-Red) dan EO (Electro-Optical) dari beberapa sumber. Dataset kedua diperoleh dari data MRI otak online milik McConnell Brain Imaging Center yang dapat diperoleh dari http://mouldy.bic.mni.mcgill.ca/brainweb/. Data tersebut terdiri dari 188 pasang gambar. Kedua gambar tersebut digabungkan sehingga terdapat 206 pasang gambar.
Metode yang diuji pada gambar monomodal adalah IS-SIFT, GO-IS-SIFT, MOG-IS-SIFT, HD-IS-SIFT, HD-GO-IS-SIFT, dan HD-MOG-IS-SIFT. Berdasarkan hasil dari 206 pasang gambar, akurasi rata-rata dari IS-SIFT, GO-IS-SIFT, MOG-IS-SIFT, HD-IS-SIFT, HD-GO-IS-SIFT dan HD-MOG-IS-SIFT masing-masing adalah 86.67%, 91.15%, 95.71%, 97.70%, 99.02%, dan 99.47%. Terlihat bahwa keempat metode yang diusulkan memiliki akurasi yang lebih baik dari pada IS-SIFT dan GO-IS-SIFT pada hampir diseluruh kasus. Selain itu, HD juga mampu membuat akurasi menjadi meningkat.
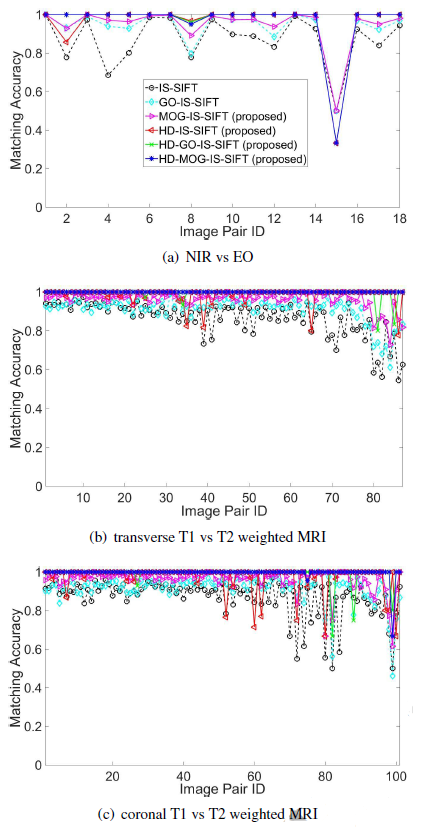
- Perbandingan efisiensi
Hasil rata-rata dari waktu proses berjalannya IS-SIFT, GO-IS-SIFT, MOG-IS-SIFT, HD-IS-SIFT, HD-GO-IS-SIFT dan HD-MOG-IS-SIFT masing-masing adalah 1.92, 1.90, 3.64, 1.96, 1.96, dan 3.62 detik. Berdasarkan hasil dari waktu komputasi, terlihat bahwa jika menggunakan MOG membuat waktu perhitungan menjadi lebih lama. Namun, dengan adanya HD tidak membuat perbedaan waktu yang sangat jauh.
4. KESIMPULAN
Terdapat dua metode yang diusulkan, pertama adalah MOG yang menggabungkan GM dan GO dalam menentukan pasangan keypoint. Metode kedua yang diusulkan adalah HD yang dapat membantu dalam seleksi pasangan keypoint yang tepat dan benar. Berdasarkan hasil yang didapat, metode yang diusulkan dapat memberikan akurasi yang lebih tinggi daripada metode-metode sebelumnya. Namun, tentu saja dengan adanya tambahan MOG waktu komputasi menjadi meningkat. Saran yang mungkin dapat dilakukan adalah dengan memberikan pembobotan dalam menggabungkan fitur GM dan GO.
5. REFERENSI
Chen, J., & Tian, J. (2009). Real-time multi-modal rigid registration based on a novel symmetric-SIFT descriptor. Progress in Natural Science, 9(5), 643–651. doi:https://doi.org/10.1016/j.pnsc.2008.06.029
Lowe, D. G. (1999). Object Recognition from Local Scale-Invariant Features. The Proceedings of the Seventh IEEE International Conference on Computer Vision, 1-8. doi:10.1109/ICCV.1999.790410
Lv, G., Teng, S. W., & Lu, G. (2016). Enhancing SIFT-based Image Registration Performance by Building and Selecting Highly Discriminating Descriptors. Pattern Recognition Letters, 1-8. doi:10.1016/j.patrec.2016.09.011
Teng, S. W., Hossain, M. T., & Lu, G. (2015). Multimodal image registration technique based on improved local feature descriptors. J. Electron. Imaging, 24(1), 1-17. doi:10.1117/1.JEI.24.1.013013
Comments :