Pengenalan Terhadap Sistem Identifikasi Bahasa Lisan
Identifikasi Bahasa Lisan (IBL), atau dalam Bahasa Inggris dikenal dengan istilah Spoken Language Identification (Muthusamy, 1994), adalah suatu proses mengidentifikasi bahasa yang dituturkan oleh seorang pembicara secara otomatis oleh sistem komputer berdasarkan sejumlah pilihan bahasa yang sudah ditentukan sebelumnya. Seperti yang diilustrasikan pada Gambar 1 di bawah ini, seorang pembicara mengucapkan sebuah frasa atau kalimat di depan suatu sistem IBL. Sistem IBL mengolah sinyal suara tersebut dan menerapkan sejumlah teknik dan algoritma IBL untuk kemudian menghasilkan nama bahasa dari frasa atau kalimat tersebut. Nama bahasa yang dihasilkan sistem terbatas pada himpunan bahasa yang sudah ditentukan sebelumnya (closed domain).
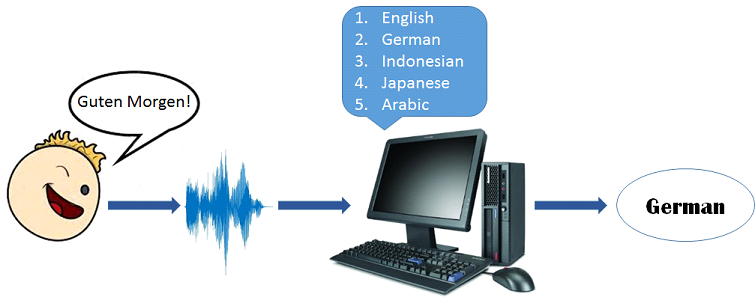
Gambar 1. Sistem Identifikasi Bahasa Lisan
Sebagai contoh, A berucap, “Guten Morgen!” Sinyal suara A kemudian diolah oleh sistem. Berdasarkan himpunan atau domain bahasa yang telah ditentukan, yaitu Bahasa Inggris, Jerman, Indonesia, Jepang, dan Arab, sistem IBL mengenali bahasa dari kalimat yang diucapkan oleh A tersebut sebagai Bahasa Jerman.
Pertanyaan selanjutnya adalah bagaimana cara membangun suatu sistem IBL? Secara garis besar, sistem IBL dibangun melalui tiga tahap pengembangan (Gambar 2), antara lain persiapan data, pelatihan model (training), dan pengujian atau evaluasi (testing).
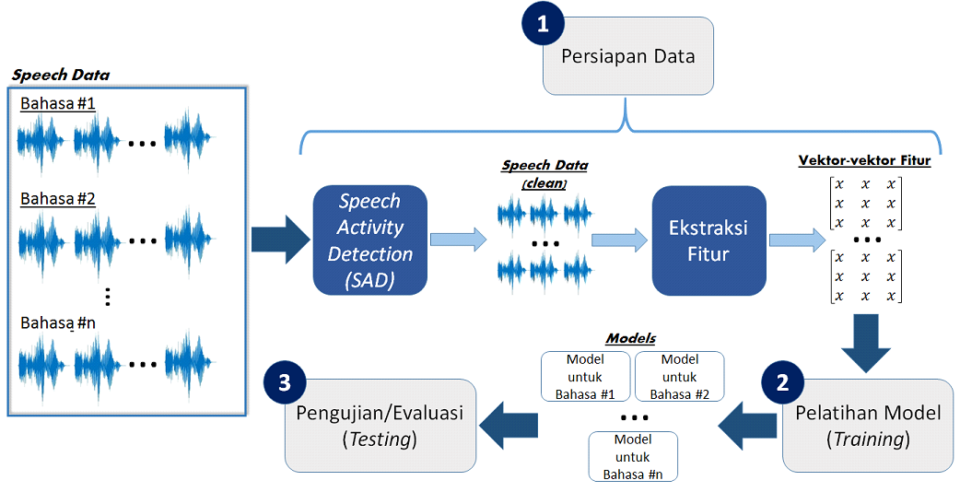
Gambar 2. Tahap-tahap Pengembangan Sistem Identifikasi Bahasa Lisan
Setiap tahap yang tertera pada Gambar 2 akan dijabarkan lebih rinci satu per satu.
Tahap 1: Persiapan Data
Dalam tahap persiapan data, data yang dibutuhkan adalah data speech beserta label nama bahasanya. Informasi lain terkait jenis kelamin dan umur pembicara dapat digunakan sebagai pelengkap jika dibutuhkan untuk kepentingan kinerja sistem.
Data speech perlu melalui proses pembersihan dengan menerapkan Speech Activity Detection (SAD), yakni suatu proses mengidentifikasi segmen ucapan manusia dalam sebuah sinyal audio (Ng, 2012). Dengan demikian, keluaran proses SAD adalah segmen-segmen berisi speech saja. Segmen-segmen ini kemudian diteruskan ke proses ekstraksi fitur. Pada tahap ini, fitur-fitur yang dianggap penting dalam membedakan suatu bahasa dengan bahasa lain diekstrak dari setiap data speech. Proses ekstraksi fitur (feature extraction) menerapkan satu atau lebih teknik atau algoritma yang tidak akan dibahas dalam artikel ini. Teknik ekstraksi fitur akan diulas di artikel-artikel selanjutnya.
Sebelum atau setelah ekstraksi fitur, data dibagi menjadi dua himpunan, yakni data untuk pelatihan model (training) dan data untuk pengujian (testing). Proporsinya beragam, namun porsi data untuk training biasanya lebih besar daripada porsi data untuk testing, misalnya 80% training dan 20% testing. Data training akan digunakan untuk membangun model setiap bahasa dalam domain. Pelatihan model akan diulas lebih jauh di Tahap 2.
Tahap 2: Pelatihan Model (Training)
Tahap berikutnya adalah pelatihan model (training) yang juga merupakan tahap penting penentu kinerja sistem IBL. Fitur-fitur hasil ekstraksi dari Tahap 1 kemudian diproses menggunakan teknik pelatihan model setiap Bahasa. Teknik yang digunakan dapat dikelompokkan menjadi dua kategori: teknik berbasis akustik dan fonetik, atau kombinasi di Antara keduanya. Sistem IBL yang menggunakan teknik berbasis akustik biasanya menerapkan algoritma Machine Learning, seperti Gaussian Mixture Model (Torres-Carrasquillo, 2002), Support Vector Machine (Campbell, 2006), Neural Network (Mary, 2004), dan masih banyak lagi. Teknik berbasis fonetik umumnya memanfaatkan informasi linguistik Bahasa-bahasa dalam domain dan sistem pengenal suara otomatis, atau dikenal dengan istilah Automatic Speech Recognition (ASR. Prinsip utama teknik-teknik tersebut adalah mencari pola yang terkandung dalam fitur-fitur suatu bahasa sedemikian hingga pola tersebut menjadi solid untuk masing-masing bahasa, dan unik antar bahasa yang berbeda. Pola tersebut kemudian dibungkus menjadi sebuah model. Dengan demikian, jumlah model yang dihasilkan sama dengan jumlah bahasa yang telah ditentukan (closed domain).
Tahap 3: Pengujian atau Evaluasi (Testing)
Model-model bahasa hasil training diuji fungsionalitas, kinerja, dan akurasinya di tahap ini. Pengujian dilakukan dengan mengucapkan frasa atau kalimat di hadapan sistem IBL. Sinyal suara yang menjadi masukan sistem juga perlu melalui proses Speech Activity Detection dan ekstraksi fitur, untuk kemudian dicocokkan dengan model-model bahasa hasil training sebelumnya untuk mengetahui kemiripan sinyal tersebut dengan bahasa-bahasa yang dapat dikenali oleh sistem IBL. Proses pencocokan ini menerapkan suatu teknik machine learning atau data mining, yang dicocokkan dengan jenis modelnya. Hasil pencocokan akan berupa suatu confidence score yang mengindikasikan seberapa besar keyakinan sistem bahwa sinyal masukan tersebut mirip dengan model-model bahasa hasil training. Bahasa dari model yang menghasilkan confidence score tertinggi akan diputuskan oleh sistem IBL menjadi bahasa dari masukan suara tersebut.
Referensi
Ng, T., et al. (2012). Developing a speech activity detection system for the DARPA RATS program. In Thirteenth Annual Conference of the International Speech Communication Association.
Mary, L. and Yegnanarayana, B. (2004). Autoassociative neural network models for language identification. In Intelligent Sensing and Information Processing, 2004. Proceedings of International Conference on (pp. 317-320). IEEE.
Campbell, W. M., et. al. (2006). Support vector machines for speaker and language recognition. Computer Speech & Language, 20(2), 210-229.
Torres-Carrasquillo, P. A., et. al. (2002). Approaches to language identification using Gaussian mixture models and shifted delta cepstral features. In Interspeech.
Muthusamy, Y. K., et. al. (1994). Reviewing automatic language identification. IEEE Signal Processing Magazine, 11(4), 33-41.
Comments :