Ingin Terapkan Data Mining? Ini Tahapannya
Kemajuan teknologi penyimpanan data modern menyebabkan data semakin beragam dan bertambah secara eksponensial setiap harinya. Data yang dihasilkan dapat berasal dari internal seperti data finansial maupun data yang berasal dari luar seperti media sosial (Facebook, WhatsApp, Instagram, dan Youtube).
Trend pertambahan data yang terus melejit ini menyebabkan ketidakseimbangan antara jumlah data yang tersedia dan kemampuan organisasi untuk menganalisisnya. Selain lambat, metode statistik tradisional yang dilakukan secara manual sangatlah tidak praktikal dan sangat melelahkan. Di sisi lain, era digital saat ini menuntut organisasi untuk mampu mengambil keputusan dengan cepat dan tepat.
Lalu bagaimana caranya memanfaatkan informasi yang tersedia untuk membantu organisasi membuat keputusan yang strategis? Sejak tahun 1990-an, sebenarnya komunitas database sudah membuat istilah explorasi data (data mining) sebagai jawaban pertanyaan diatas. Secara sederhana, data mining adalah proses ekstraksi informasi yang dapat dimodelkan secara eksplisit dan dimanfaatkan untuk pembuatan keputusan dari sumber data yang tersedia.
Metodologi Data Mining
Terlepas dari jenis dan tipe data yang dimiliki organisasi, terdapat setidaknya tiga metodologi yang biasa digunakan untuk melakukan data mining:
- CRISP-DM – awalnya dibangun oleh 3 perusahaan yaitu SPSS, Daimler Chrysler, dan NCR yang kemudian dikembangan ratusan organisasi dan perusahaan secara bersama-sama. CRISP-DM merupakan singkatan dari Cross-Industry Standard Process for Data Mining dan memiliki 6 tahapan yaitu Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, dan Deployment.
- SEMMA – dibangun oleh SAS Institute, sebuah perusahaan software Sesuai kepanjangannya, SEMMA memiliki 5 tahapan untuk melakukan eksplorasi data yaitu: Sample, Explore, Modify, Model, dan Assess.
- Knowledge Discovery Process – diusulkan oleh Fayyad pada tahun 1996. Proses ekstraksi pengetahuan ini memiliki 5 tahapan yang akan dibahas di bawah ini.
Pada artikel ini, saya hanya akan membahas metodologi Knowledge Discovery Process karena lebih populer secara akademik dibandingkan CRISP-DM dan SEMMA.
Knowledge Discovery Process
Secara garis besar, proses ekstraksi pengetahuan dari data terdiri dari 5 proses seperti pada gambar 1.
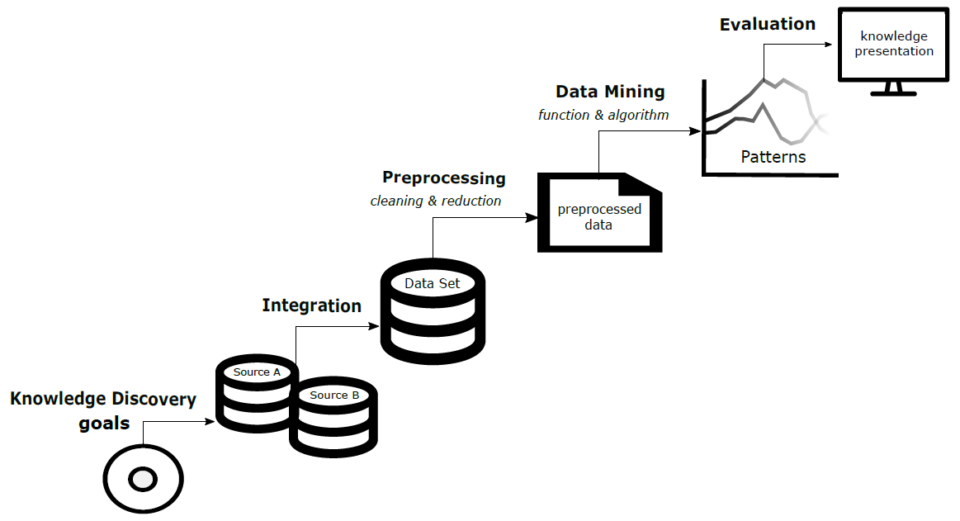
Gambar 1 Proses ekstraksi pengetahuan dari sumber data
Proses ini terdiri dari lima langkah utama yaitu .
Tahapan 1: Knowledge discovery goals
Langkah pertama dalam mengerjakan sebuah aktifitas data mining adalah mengidentifikasi kebutuhan bisnis atau organisasi berdasarkan permasalahan yang dihadapi. Data mining dapat digunakan untuk tujuan-tujuan berikut ini:
- Analisis asosiasi – mencari produk dan/atau jasa yang sering muncul secara bersamaan.
- Pengelompokkan – mengelompokkan data menjadi kelompok-kelompok yang lebih kecil berdasarkan kemiripannya.
- Ringkasan data – meringkas data kepada bentuk representasi yang lebih singkat.
- Analisis regresi – memodelkan hubungan antar atribut menjadi sebuah fungsi matematik untuk memprediksi nilai yang tidak diketahui atau nilai yang hilang.
- Klasifikasi – membuat sebuah model yang dilatih untuk memprediksi suatu atribut berdasarkan atribut lainnya. Beda regresi dengan klasifikasi adalah pada regresi atribut yang diprediksi bersifat kontinu sedangkan pada klasifikasi atribut yang diprediksi bersifat kategorikal.
- Deteksi penyimpangan – mengidentifikasi data yang tidak sesuai dengan perilaku umum data lainnya
Tahapan 2: Data Integration
Sesuai dengan tujuan kegiatan data mining, maka asal muasal sumber data akan ditentukan, dikumpulkan dan digabungkan menjadi sebuah data target. Jika domain aplikasi cukup besar, maka data target bisa berbentuk data warehouse ataupun data mart. Biasanya, tidak semua atribut data akan digunakan sehingga data dapat diseleksi dulu berdasarkan subset atribut yang relevan saja sehingga menjadi sebuah dataset.
Tahapan 3: Data Preprocessing
Dataset yang dihasilkan seringkali bersifat mentah dan kurang berkualitas, misal terdapat nilai yang hilang, salah input nilai, dan tidak konsisten. Akibatnya perlu dilakukan prapemrosesan data terlebih dahulu. Proses pembersihan mencakup menghilangkan duplikasi data, mengisi / membuang data yang hilang, memperbaiki data yang tidak konsisten, dan memperbaiki kesalahan ketik.
Meskipun data telah disempurnakan dan dibersihkan, kualitas data dapat ditingkatkan dengan menormalisir rentang data ataupun dengan menemukan representasi data yang lebih sedikit dari data aslinya.
Tahapan 4: Data Mining
Data yang telah diformat sekarang siap untuk diproses menggunakan algoritma data mining. Proses ini merupakan inti dari proses ekstraksi pengetahuan dari data. Algoritma / metode akan dipilih sesuai dengan tujuan kegiatan data mining yang telah ditentukan pada tahapan yang pertama. Seni pada tahapan ini adalah mencari parameter terbaik untuk menghasilkan model pengetahuan yang paling berguna untuk membantu pembuatan keputusan.
Tahapan 5: Knowledge Evaluation
Model pengetahuan yang ditemukan perlu ditampilkan dalam bentuk yang mudah dimengerti bagi pihak yang berkepentingan. Model pengetahuan yang dihasilkan dari proses data mining juga harus dievaluasi dan ditafsirkan berdasarkan ukuran tertentu. Untuk tujuan pembuatan model klasifikasi, contoh ukurannya adalah akurasi dan efisiensi dari metode yang digunakan. Jika akurasi rendah, maka model ini akan kurang berguna untuk implementasinya. Untuk meningkatkan akurasi, anda perlu memperbaiki ataupun mengganti model ataupun metode klasifikasi yang digunakan, baik pada tahapan preprocessing maupun pada tahapan data mining.
Tahapan-tahapan di atas merupakan resep tahapan baku yang biasa digunakan dalam menemukan model eksplisit pengetahuan dari sumber data yang tersedia. Namun demikian, setiap tujuan aktifitas data mining memiliki best-practice masing-masing baik dari segi metode maupun parameter yang akan digunakan. Misal, metode klasifikasi data yang paling sering digunakan saat ini adalah deep learning dengan parameter hidden layer yang dapat berjumlah ratusan. Untuk mengetahui best-practice dari masing-masing tujuan data mining, kita dapat membaca artikel / makalah akademik yang berkaitan.
Comments :