Teknik Klasifikasi Bug dengan Tiketing
Dalam proses pembuatan software, intensitas kemunculan bug relatif tinggi. Bug adalah penyebab kegagalan dari suatu software (Liblit B. , Naik, Zheng, Aiken, & Michael I., 2005). Hal itu membuat diperlukannya sebuah sistem yang dapat menampung semua bug yang muncul. Sistem tersebut akan berfungsi sebagai tempat penampungan bug dan sebagai sistem yang bertugas untuk melakukan klasifikasi bug yang ada kepada para developer yang kompeten dalam rangka untuk diperbaiki. Tujuan utama dari proses klasifikasi bug adalah agar bug yang ada dapat di verifikasi dan diperbaiki oleh developer yang memang berkompeten dibidangnya (Xuan, Jiang, Ren, Yan, & Luo, 2010). Sehingga proses perbaikan bug tersebut dapat berjalan efektif dan keseluruhan sistem dapat berjalan lebih optimal tanpa adanya bug lagi. Oleh karena itu masalah klasifikasi bug menjadi isu penting dalam membangun software.
Klasifikasi bug (bugs triaging) adalah suatu proses dimana bug yang muncul harus di berikan kepada developer yang berkompeten dalam rangka untuk diperbaiki (Xuan, Jiang, Ren, Yan, & Luo, 2010). Proses ini adalah suatu proses yang wajib dilakukan terlebih dahulu sebelum bug yang ada di verifikasi dan di perbaiki.
Saat ini akan dibahas teknik klasifikasi bug otomatis ke dalam suatu sistem ticketing.
Sistem tiketing adalah suatu sistem yang berfungsi untuk mendata seluruh bug yang muncul. Dimana bug- bug tersebut di input oleh user, lalu kemudian akan di berikan kepada developer yang berkompeten untuk di perbaiki. Proses klasifikasi bug untuk kemudian diberikan kepada developer tersebut sebelumnya selalu dilakukan secara manual. Seiring berjalannya waktu dan pertambahan bug yang muncul proses manual ini dirasa mulai menghambat, karena itu diperlukan suatu optimasi proses, dimana merubah proses klasifikasi yang sebelumnya manual menjadi otomatis. Proses klasifikasi bug tersebut didasari atas nama aplikasinya. Dimana untuk setiap bug yang masuk, akan dilakukan proses klasfikasi otomatis berdasarkan nama aplikasinya.Salah sau klasifikasi optimalisasi menggunakan A fast string searching algorithm (Boyer & Moore, 1977) . A fast string searching algorithm adalah sebuah algoritma pencarian kata di dalam sebuah kalimat. Dimana ide dasarnya adalah akan lebih banyak informasi dan kesamaan yang kita dapatkan apabila dilakukan pencarian yang dimulai dari sebelah kanan.
Algoritma A fast string searching algorithm memiliki beberapa keunggulan lebih dibandingkan dengan algoritma pencarian teks lainnya. Selain karena algoritma ini memang sesuai dengan karakterisik dari bugs yang ada, algoritma ini berfungsi lebih baik daripada algoritma knuth morris algorithm, dimana algoritma ini lebih cocok untuk string binary.
Seperti terlihat pada Gambar 1 dibawah ini, adalah notasi algoritma dari A fast string searching algorithm.
Gambar 1. Notasi Algoritma (Boyer & Moore, 1977)
Sedangkan pada Gambar 2 dibawah ini, terlihat alur proses kerja dari algoritmanya. Dimana kata yang ingin dicari dilambangkan sebagai ‘pat’. Dan kalimat yang ingin dilakukan pencarian dilambangkan sebagai ‘String’. Lalu tanda panah pertama, dihuruf paling kanan pada pat.

Gambar 2. Step Algoritma (Boyer & Moore, 1977)
Seperti terlihat pada gambar 2 diatas, proses pertama dimulai dengan mensejajarkan pat dan string di paling kiri kata dan kalimatnya.Selanjutnya memeriksa apakah huruf terakhir pada pat sama dengan huruf yang berada pada urutan index yang sama di string. Jika dirasa karakter huruf yang dicari berbeda dan tidak ada sama sekali pada pat, maka pat akan dimajukan 1 karakter setelah index dari huruf terakhir pat yang terakhir kali dicocokan.Pada proses selanjutnya tahapan yang sama dilakukan kembali. Proses terus berulang sampai ditemukan karakter yg sama. Apabila terdapat karater yang sama, selanjutnya index pengecekan akan bergerak mundur untuk mengecek karakter lainnya. Jika belum diperoleh kesamaan, proses pertama akan kembali di ulang hingga di temukan karakter yang persis sama. Jika juga dalam perjalanan ditemukan huruf yang dicari, namun posisi dari huruf tersebut ada di tengah-tengah kata pat, maka pat akan dimajukan sejumlah m karakter antara posisi terakhir huruf sebelum pencocokan dengan letak karakter yg dicari ditemukan didalam pat.
Jika sudah ditemukan seluruh karakter yang memiliki kesamaan arti, kata yang dicari sudah berhasil temukan. Seperti terlihat pada gambar 3 di bawah, bahwa sebuah bugs itu hanya memiliki 2 parameter utama yang perlu diperhatikan, yaitu deskripsi dari bug itu sendiri dan aplikasi dimana bug itu berada. Keseluruhan parameter itu ditulis dalam bentuk 1 tulisan teks. Hal ini membuat diperlukan sebuah algoritma pencarian teks untuk menemukan parameter – parameter tersebut. Terutama parameter nama aplikasinya. Agar supaya bug tersebut dapat langsung diklasifikasikan kepada developer yang memiliki kompetensi aplikasi yang sesuai.
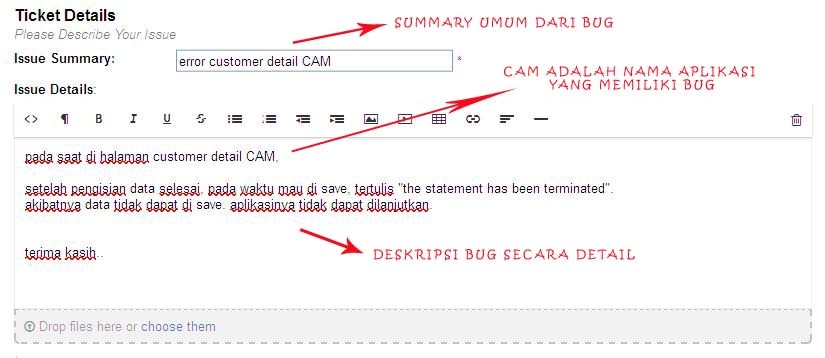
Gambar 3. Contoh Bug Sistem Os Ticket
Danar Ardhito (2016), Optimalisasi Klasifikasi Bugs pada Sistem Tiketing di PT. Selaras Anugerah Lestari” Tesis
Liblit, B., Naik, M., Zheng, A. X., Aiken, A., & Michael I., J. (2005). Scalable Statistical Bug Isolation.
Xuan, J., Jiang, H., Ren, Z., Yan, J., & Luo, Z. (2010). Automatic Bug Triage using Semi-Supervised Text. In SEKE, 209-2014.
Boyer, R., & Moore, J. (1977). A fast string searching algorithm. Communications of the ACM, 762-772.
Comments :