Apache STORM
oleh:
Dimas Aji Pamungkas (1801659855)
Eduard Pangestu Wonohardjo (1801657591)
Rizky Febriyanto Sunaryo (1801657540)
Yusuf Sudiyono (1801657553)
APACHE STORM
Apache Storm adalah sistem komputasi real-time terdistribusi untuk memproses jumlah data yang besaryang sangat cepat secara paralel dan skala. Storm adalah pemrosesan data realtime seperti Apache Hadoop dan MapReduce untuk pemrosesan data batch. Dengan antarmuka pemrograman yang sederhana, Storm memungkinkan pengembang aplikasi untuk membuat aplikasi yang menganalisis aliran data tuple; sebuah tupel mungkin bisa berisi objek dari jenis apapun. *Tuple adalah kumpulan elemen data yang dikumpulkan menjadi satu kesatuan dengan tipe data.
Inti dari pemrosesan data stream Storm adalah topologi komputasi, yang akan dibahas di bawah ini. Topologi node ini menentukan bagaimana tuple diproses, diubah, digabungkan, disimpan, atau didistribusikan kembali ke node lain di topologi untuk diproses lebih lanjut.
Storm on YARN bertenaga untuk skenario yang memerlukan analisis terus menerus, prediksi waktu realtime, dan pemantauan operasi yang berkesinambungan. Perusahaan menggunakan manfaat Storm on YARN pada penghematan biaya (dengan mengakses dataset yang sama dari mesin dan aplikasi lain pada kelompok yang sama) dan keamanan, pengelolaan data, dan operasional.
Storm dalam perusahaan
Beberapa peluang bisnis baru yang spesifik meliputi: manajemen layanan pelanggan real-time, monetisasi data, Dashboard operasional, atau analisis keamanan cyber dan deteksi ancaman.
Stormsangat cepat dalam melakukan pemroses lebih dari satu juta catatan per detik per node pada satu cluster.
Dengan Storm di YARN, sebuah cluster Hadoop dapat memproses secara efisien berbagai beban kerja dari waktu-nyata menjadi interaktif ke batch. Storm itu sangat sederhana, dan pengembang bisa menulis topologi Storm menggunakan bahasa pemrograman apa pun.
Lima karakteristik membuat Storm ideal untuk beban kerja pemrosesan data real-time, adalah:
- Fast – benchmarked sebagai pengolahan satu juta pesan 100 byte per detik per node
- Scalable – dengan perhitungan paralel yang berjalan di sekumpulan mesin
- Fault-tolerant – Storm dapat secara otomatis akan me-restart nodes yang mati.
- Reliable – Storm menjamin bahwa setiap unit data (tuple) akan diproses setidaknya sekali atau tepat satu kali. Pesan hanya diputar ulang bila ada kegagalan.
- Mudah dioperasikan – konfigurasi standar sehingga mudah untuk di implementasikan dan dioperasikan.
Cara Storm bekerja
Sebuah cluster Storm memiliki tiga set node:
- Nimbus node (master node, mirip dengan Hadoop JobTracker):
o perhitungan Upload untuk eksekusi
o Mendistribusikan kode ke seluruh cluster
o memerintahkan workerske seluruh cluster
o Monitor dan realokasi workers sesuai kebutuhan
- ZooKeeper Nodes – koordinat cluster Storm
- Supervisor Nodes – berkomunikasi dengan Nimbus melalui Zookeeper, memulai dan menghentikan workers sesuai intruksi dari Nimbus
Pengguna Storm menentukan topologi bagaimana memproses data saat streaming dari cerat. Saat data masuk, diproses dan hasilnya dilewatkan ke baut lain atau disimpan di Hadoop.
Pelajari lebih lanjut tentang bagaimana komunitas bekerja untuk mengintegrasikan Storm dengan Hadoop dan memperbaiki kesiapannya untuk perusahaan tersebut.
Topologi Storm
Cluster Storm mirip dengan cluster Hadoop. Sedangkan pada Hadoop Anda menjalankan “pekerjaan MapReduce,” pada Storm Anda menjalankan “topologi.” “Pekerjaan” dan “topologies” berbeda – satu perbedaan utama adalah bahwa sebuah pekerjaan MapReduce memiliki akhir, sedangkan sebuah proses topologi pesan selamanya berjalan (atau sampai diberhentikan ).
Ada dua jenis node pada cluster Storm: node master dan node pekerja. Simpul master menjalankan daemon yang disebut “Nimbus” yang mirip dengan “JobTracker” milik Hadoop. Nimbus bertanggung jawab untuk mendistribusikan kode seputar cluster, menugaskan tugas ke mesin, dan memantau kegagalan.
Setiap node pekerja menjalankan daemon yang disebut “Supervisor”. Ini memantau pekerjaan yang ditugaskan ke mesinnya dan memulai dan menghentikan proses pekerja seperti yang didiktekan oleh Nimbus. Setiap proses pekerja mengeksekusi sebagian topologi; topologi yang berjalan terdiri dari banyak proses pekerja yang tersebar di banyak mesin.
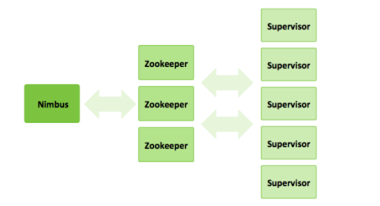
Gambar 1. Architecturestorm cluster[1]
Komponen cluster StormSecara Detail[2]:
- Master Node (Nimbus)
Nimbus yang mirip dengan JobTracker milik Hadoopbertanggung jawab untuk mendistribusikan kode seputar cluster, menugaskan tugas ke mesindan memantau kegagalan.Nimbus adalah layanan Apache Thrift yang memungkinkan Anda mengirimkan kode ke bahasa pemrograman apapun. Dengan cara ini, Anda selalu bisa memanfaatkan bahasa yang Anda mahir tanpa perlu belajar bahasa baru untuk memanfaatkan Apache Storm.Layanan Nimbus bergantung pada Apache ZooKeeper untuk memantau tugas pemrosesan pesan karena semua node pekerja memperbarui status tugas mereka di layanan Apache ZooKeeper.
- Worker Nodes (Supervisor)
Setiap node pekerja menjalankan daemon yang disebut Supervisor. Supervisor mendengarkan pekerjaan yang ditugaskan ke mesinnya dan memulai dan menghentikan proses pekerja seperlunya berdasarkan apa yang ditugaskan Nimbus kepadanya. Setiap proses pekerja mengeksekusi sebagian topologi.Topologi yang berjalan terdiri dari banyak proses pekerja yang tersebar di banyak mesin.
Semua koordinasi antara Nimbus dan Supervisor dilakukan melalui cluster ZooKeeper. Selain itu, daemon Nimbus dan Supervisor daemon kegagalancepat dan tanpa status. Meskipun sifat tanpa status memiliki kekurangan tersendiri, namun sebenarnya membantu proses Storm data real-time menjadi yang terbaik dan tercepat.
Storm tidak sepenuhnya tanpa status. Ini merupakan bagian di Apache ZooKeeper. Karena bagian tersebut tersedia di Apache ZooKeeper, Nimbus yang gagal dapat dimulai ulang dan dibuat untuk bekerja dari tempat yang ditinggalkannya. Alat pemantau layanan dapat memantau Nimbus dan menyalakannya kembali jika terjadi kegagalan.
Apache Storm juga memiliki topologi lanjutan bernama Trident Topology dengan state maintenance. dan juga menyediakan API tingkat tinggi seperti Bintang Babi.
Apache Storm juga memiliki topologi lanjutan bernama Trident Topology dengan state maintenance. dan juga menyediakan API tingkat tinggi seperti Babi.
- Topologies
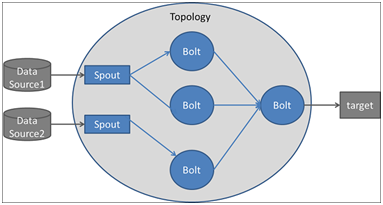
Untuk melakukan perhitungan real-time pada Storm, Anda menciptakan apa yang disebut topologi . Sebuah topologi adalah grafik perhitungan dan diimplementasikan sebagai struktur data DAG (directed asyclic graph).Setiap node dalam topologi berisi logika pemrosesan (bolts) dan hubungan antar node menunjukkan bagaimana data harus dilalui di antara node (stream).
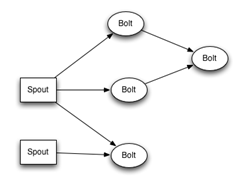
Ketika topologi diajukan ke cluster Storm, layanan Nimbus pada node master berkonsultasi dengan supervisor mengenai node pekerja yang berbeda dan mengirimkan topologi. Setiap supervisor menciptakan satu atau lebih proses pekerja, masing-masing memiliki JVM tersendiri. Setiap proses berjalan dengan sendirinya yang kita sebut Pelaksana.
Thread / pelaksana memproses tugas komputasi yang sebenarnya: Spout or Bolt.
Menjalankan topologi sangatlah mudah. Pertama, Anda mengemas semua kode dan dependensi Anda ke dalam satu JAR. Kemudian, Anda menjalankan perintah seperti berikut:
Aliran mewakili urutan tupel yang tak terbatas (kumpulan pasangan nilai kunci) di mana tuple adalah unit data.
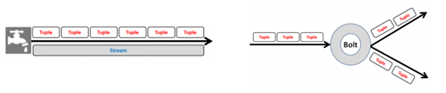
Aliran tupel mengalir dari moncong ke bolt(s) atau dari boltke boltlain (s). Ada berbagai teknik pengelompokan arus untuk membiarkan Anda menentukan bagaimana data harus mengalir dalam topologi seperti pengelompokan global, dll.
- Spouts
adalah titik masuk dalam topologi Storm. Ini merupakan sumber data di Storm. Umumnya, spouts akan membaca tupel dari sumber eksternal dan memancarkannya ke topologi. Anda dapat menulis spouts untuk membaca data dari sumber data seperti database, sistem berkas terdistribusi, kerangka pesan, atau antrian pesan seperti Kafka dari mana ia mendapatkan data terus menerus, mengubah data aktual menjadi aliran tupel, dan memancarkannya ke baut. untuk pemrosesan sebenarnya Spouts dijalankan sebagai tugas dalam proses pekerja oleh benang Pelaksana.Spouts secara luas dapat diklasifikasikan sebagai berikut:
- Reliable : Spouts ini memiliki kemampuan untuk memutar ulang tupel (satu unit data dalam aliran data). Ini membantu aplikasi mencapai “setidaknya sekali pemrosesan pesan” semantik seperti, jika terjadi kegagalan, tupel dapat diputar ulang dan diproses lagi. Spouts untuk mengambil data dari kerangka pesan umumnya dapat diandalkan, karena kerangka kerja ini menyediakan mekanisme untuk memutar ulang pesan.
- Unreliable : Spam ini tidak memiliki kemampuan untuk memutar ulang tupel. Begitu tupel dipancarkan, tidak bisa diputar ulang, terlepas dari apakah berhasil diproses. Jenis cerat berikut “paling banyak sekali pemrosesan pesan” semantik.
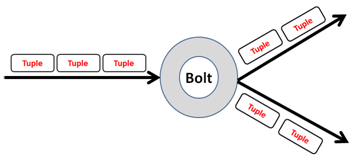
- Bolts
Semua proses di topologi dilakukan dengan bolts. Boltsbisa melakukan apapun dari penyaringan dan fungsi ke agregasi, bergabung, berbicara dengan database, dan banyak lagi.Bolts bisa melakukan transformasi arus sederhana. Melakukan transformasi aliran yang kompleks sering membutuhkan banyak langkah dan dengan demikian banyak bolts. Misalnya, mengubah aliran tweet ke dalam arus gambar yang sedang tren memerlukan setidaknya dua langkah: sebuah baut untuk melakukan hitungan retweet untuk setiap gambar dan satu atau lebih baut untuk mengalirkan gambar X teratas (Anda dapat melakukan hal ini secara khusus transformasi arus dengan cara yang lebih terukur dengan tiga baut daripada dua).
Manfaat Menggunakan Apache Storm[3]:
- Real-time stream processing.
- Skalabilitas, di mana tingkat throughput bahkan satu juta pesan 100 byte per detik per node dapat dicapai.
- low latency.Storm melakukan refresh data dan respons pengiriman dari ujung ke ujung dalam hitungan detik atau menit tergantung pada masalahnya.
- Reliable . Storm menjamin bahwa setiap unit data (tupel) akan diproses setidaknya satu kali atau tepat satu kali. Pesan hanya diputar ulang bila ada kegagalan.
- Easy to operate . Konfigurasi standar cocok untuk produksi pada hari pertama. Setelah dikerahkan, Storm mudah dioperasikan.
- Fault-tolerant : Kemampuan untuk menjadi fault tolerant sangat penting bagi Storm, karena mengolah data masif setiap saat dan tidak boleh terganggu oleh kegagalan minimal, seperti kegagalan hardware pada node cluster badai. Badai dapat memindahkan tugas saat diperlukan.
- Data guarantee : Tidak ada kehilangan data adalah salah satu persyaratan penting untuk sistem pengolahan data. Risiko kehilangan data tidak akan diterima dalam penggunaan sebagian besar bidang, terutama bila menyangkut hasil yang akurat. Storm memastikan bahwa semua data akan diproses karena dirancang selama pemrosesannya di topologi.
- Kemudahan penggunaan dalam penggelaran dan pengoperasian sistem .
- Dukungan untuk beberapa bahasa pemrograman .
- Dengan data yg di proses secara real time, maka penipuan yang terjadi bisa dideteksi secara cepat dan tindakan yang tepat bisa dilakukan untuk membatasi kerusakan.
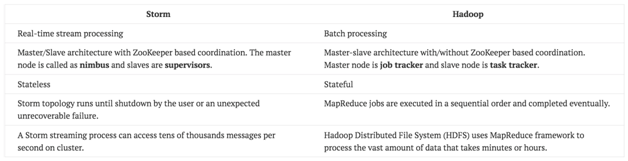
Apache Storm vs. Hadoop
Kerangka kerja Hadoop dan Storm keduanya secara fundamental digunakan untuk menganalisis data yang besar. Keduanya saling melengkapi dan berbeda dalam beberapa aspek. Apache Storm melakukan semua operasi kecuali persistensi, sementara Hadoop bagus dalam segala hal kecuali kelambatan dalam perhitungan real-time. Tabel berikut membandingkan atribut Storm dan Hadoop.
Daftar Pustaka
[1] K. Patel, Y. Sakaria, and C. Bhadane, “Real Time Data Processing Frameworks,” Int. J. Data Min. Knowl. Manag. Process, vol. 5, no. 5, pp. 49–63, 2015.
[2] Ayush Tiwari, “Apache Storm: Arsitektur,” 2017. [Online]. Available: https://dzone.com/articles/apache-storm-architecture?fromrel=true. [Accessed: 24-Jan-2018].
[3] Ayush Tiwari, “Apache Storm: The Hadoop of Real-Time,” 2017. [Online]. Available: https://dzone.com/articles/apache-storm-the-hadoop-of-real-time-1. [Accessed: 24-Jan-2018].
[4] Hortonworks Inc. 2017. Realtime Event Processing in Hadoop with NiFi, Kafka and Storm. https://hortonworks.com/tutorial/realtime-event-processing-in-hadoop-with-nifi-kafka-and-storm/section/1/
Comments :