Apache HIVE
Oleh :
Dimas Aji Pamungkas (1801659855)
Eduard Pangestu Wonohardjo (1801657591)
Rizky Febriyanto Sunaryo (1801657540)
Yusuf Sudiyono (1801657553)
Pengertian Hive
Apache Hive adalah proyek open source yang dijalankan oleh relawan di Apache Software Foundation. Hive merupakan suatu infrastruktur datawarehousing untuk Hadoop. Fungsi utama dari Hive adalah untuk menyediakan data summarization, query dan analisis. Hive juga mendukung analisis dataset berukuran besar yang tersimpan di HDFS Hadoop dan juga pada filesystem Amazon S3. Hive mendukung perintah yang mirip dengan SQL seperti akses ke data terstruktur yang dikenal dengan istilah Hive-QL (atau HQL) serta analisis data yang besar dengan bantuan MapReduce. Hive tidak dibangun untuk mendapatkan respon cepat terhadap query namun dibuat terutama untuk aplikasi data mining. Aplikasi data mining dapat memakan waktu beberapa menit hingga beberapa jam untuk menganalisis data dan Hive terutama digunakan di sana.
Organisasi Hive
Ada 3 format data yang digunakan dalam Hive yaitu:
Tabel: Tabel dalam Hive sangat mirip dengan tabel RDBMS yang juga berisi baris dan tabel. Hive hanya dilapisi dengan Hadoop File System (HDFS), oleh karena itu tabel dipetakan secara langsung ke direktori filesystem. Ini juga mendukung tabel yang tersimpan dalam sistem file asli lainnya.
Partisi: tabel Hive bisa memiliki lebih dari satu partisi. Mereka dipetakan ke subdirektori dan sistem file juga.
Bucket: Dalam data Hive dapat dibagi menjadi bucket. Bucket disimpan sebagai file dalam partisi pada sistem file yang mendasarinya.
Hive juga memiliki metastore yang menyimpan semua metadata. Ini adalah database relasional yang berisi berbagai informasi yang berkaitan dengan Skema Hive (jenis kolom, pemilik, data nilai kunci, statistik, dll.). Kita bisa menggunakan database MySQL disini.
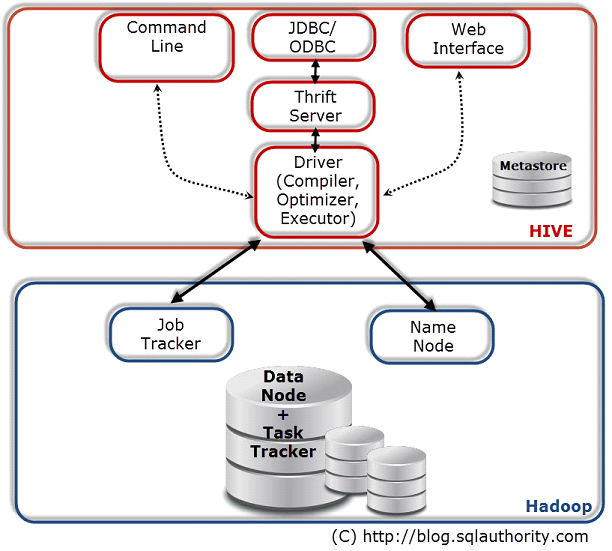
Hive-QL (HQL)
Hive-QL (HQL)Hive-QL atau Hive Query Language adalah suatu bahasa query yang mirip dengan SQL yang digunakan dalam Hive. Berikut ini adalah beberapa hal yang bisa dilakukan HQL dengan mudah.
- Membuat dan mengelola tabel dan partisi
- Mendukung berbagai Operator Relasional, Aritmatika dan Logika
- Mengevaluasi fungsi
- Mengunduh isi tabel ke direktori lokal atau hasil query ke direktori HDFS
Contoh perintah HQL:
- select NIM, Nama FROM Mhs
- select Mhs.Nama, Mhs_Detail.MatKul FROM Mhs JOIN Mhs_Detail ON (Mhs.NIM = Mhs_Detail.NIM)
Studi Kasus
Dalam studi kasus ini diberikan contoh penggunaan Hive dalam Hadoop sehingga didapatkan gambaran bagaimana cara menggunakan Hive dengan bahasa yang mirip dengan bahasa SQL.
- Command untuk start service dalam Hadoop $ start-all.sh
- Command untuk menjalankan service Hive $ hive
Managing tables
- Melihat tables hive>show tables;
- Melihat Schema hive>Describe mytable;
- Mengganti nama table hive> ALTER TABLE mytablename RENAME to mt;
- Menambah colom hive>ALTER TABLE mytable ADD COLOUMNS (mycol STRING);
- Membuang partisi hive>ALTER TABLE mytable DROP PARTITION (age=17);
Loading data
Import data kedalam Hive hive>LOAD DATA LOCAL INPATH ‘path of input data’ INTO TABLE mytable;
Insert
Insert table dari table Hive yang lain hive>CREATE TABLE age_count(name STRING,age INT);
Overwrite table hive>INSERT OVERWRITE TABLE age_count
SELECT age,COUNT(age) FROM mytable;
Dalam studi kasus ini digunakan dataset cricket.csv. attributnya berupa: name, country, Player_iD, Year.stint, teamid, run, igl, D, G, G_batting.AB, R, H, 2B, 3B, HR, RBI, SB, CS, BB, SO, IBB, HBP, SH, SF, GIDP, G_OLD.
- Create Table in Hive
hive>create table temp_cricket (col_value STRING);
- Load the Data dari csv file to table
temp_battinghive> LOAD DATA INPATH ‘/user/sai/sampledataset/hivedataset/cricket.csv’ OVERWRITE INTO TABLE temp_cricket;
- Create table lain untuk Extract data
hive>create table batting (player_id STRING,year INT, runs INT);
- Insert data ke dalam data baru setelah di extract
hive>insert overwrite table batting SELECT regexp_extract(col_value, ‘^(?:([^,]*)\,?){1}’,3) player_id, regexp_extract(col_value, ‘^(?:([^,]*)\,?){2}’,4) year, regexp_extract(col_value, ‘^(?:([^,]*)\,?){9}’,7) run from temp_cricket;Query di atas digunakan untuk meload player_id, year, run data dari tabel temp_cricket ke dalam tabel batting.
- Load data untuk menampilkan tahun dan maximum lari pertahun
hive> SELECT year, max(runs) FROM batting GROUP BY year;
REFERENSI
https://blog.sqlauthority.com/2013/10/21/big-data-data-mining-with-hive-what-is-hive-what-is-hiveql-hql-day-15-of-21/https://www.researchgate.net/publication/314724458_CASE_STUDY_OF_HIVE_USING_HADOOPhttps://hortonworks.com/apache/hive/https://hive.apache.org/index.html
Comments :