Hadoop Distributed File System (HDFS)
Pengenalan
HDFS adalah open source project yang dikembangkan oleh Apache Software Foundation dan merupakan subproject dari Apache Hadoop. Apache mengembangkan HDFS berdasarkan konsep dari Google File System (GFS) dan oleh karenanya sangat mirip dengan GFS baik ditinjau dari konsep logika, struktur fisik, maupun cara kerjanya. Sebagai layer penyimpanan data di Hadoop, HDFS adalah sebuah sistem file berbasis Java yang fault-tolerant, terdistribusi, dan scalable. Dirancang agar dapat diaplikasikan pada kluster dan dapat dijalankan dengan menggunakan proprietary atau commodity server. HDFS ini pada dasarnya adalah sebuah direktori dimana data disimpan yang bekerja sesuai dengan spesifikasi dari Hadoop. Data tersimpan dalam kluster yang terdiri dari banyak node komputer/server yang masing-masing sudah terinstalasi Hadoop.
Sistem penyimpanan terdistribusi pada HDFS melakukan proses pemecahan file besar menjadi bagian-bagian lebih kecil dan kemudian didistribusikan ke kluster-kluster sehingga memungkinkan pemrosesan secara pararel. HDFS memiliki banyak kesamaan dengan sistem file terdistribusi lainnya, nanum perbedaan yang terutama adalah model Write-Once-Read-Many (WORM) pada HDFS yang melonggarkan persyaratan kontrol konkurensi, menyederhanakan koherensi data, dan memungkinkan akses throughput yang tinggi. HDFS memiliki fitur-fitur sebagai berikut:
- Sangat sesuai untuk penyimpanan, pengelolaan dan pemrosesan dataset yang besar secara terdistribusi.
- Hadoop menyediakan antarmuka perintah untuk berinteraksi dengan HDFS.
- Heartbeat memudahkan pemeriksaan status kluster.
- Akses data melalui MapReduce streaming.
- HDFS menyediakan file permissions and authentication.
- Fault detection dan recovery.
- Lokasi komputasi berada dekat dengan data untuk mengurangi traffic jaringan dan meningkatkan throughput.
Model data dan struktur HDFS
Sebagai distributed file system, HDFS menyimpan suatu data dengan cara membaginya menjadi potong-potongan data yang disebut blok berukuran 64 MB dan kemudian disimpan pada node-node yang tersebar dalam kluster. Ukuran blok tidak terpaku pada nilai tertentu sehingga dapat diatur sesuai kebutuhan. Walaupun data disimpan secara tersebar, namun dari sudut pandang pengguna, data tetap terlihat utuh dan diperlakukan seperti halnya mengakses file pada satu media penyimpanan. Berbeda dengan sistem file pada umumnya, HDFS dapat bertumbuh tanpa batas, karena secara arsitektur dan administrasinya dapat menambah jumlah node sesuai kebutuhan. Abstraksi satu file yang berada di beberapa node memungkinkan ukuran file bertumbuh tanpa batas.
HDFS memiliki komponen utama yaitu namenode dan datanode. Namenode adalah sebuah node yang bertindak sebagai master, sedangkan datanode adalah node-node dalam kluster yang bertindak sebagai slave. Namenode bertanggung-jawab menyimpan, mengorganisir dan mengontrol blok-blok data yang disimpan pada node-node yang tersebar dalam kluster. Datanode bertanggung-jawab menyimpan blok-blok data yang ditujukan kepadanya, dan secara berkala melaporkan kondisinya kepada namenode. Jadi, namenode seperti manager yang mengatur dan mengendalikan kluster. Sedangkan, datanode seperti worker yang bertugas menyimpan data dan melaksanakan perintah dari namenode.
Setiap data yang disimpan pada HDFS memiliki lebih dari satu salinan, yang disebut sebagai Replication Factor (RF). Secara default nilai RF adalah 3, yang berarti satu file tersimpan di 3 datanode berbeda sehingga jika salah satu datanode rusak, maka file dapat diperoleh dari datanode lain. Datanode mengirimkan sinyal setiap 3 detik yang disebut heartbeat kepada namenode untuk menunjukkan bahwa datanode tersebut masih aktif. Apabila dalam 10 menit namenode tidak menerima heartbeat dari datanode, maka datanode tersebut dianggap rusak atau tidak berfungsi sehingga setiap permintaan baca/tulis dialihkan ke node lain. Dengan heartbeat, maka namenode dapat mengetahui dan menguasai kondisi kluster secara keseluruhan. Sebagai respon atas heartbeat dari datanode, selanjutnya namenode akan mengirimkan perintah kepada datanode.

Gambar 1. Arsitektur HDFS [8]
Cara kerja HDFS
Sebuah kluster HDFS yang terdiri dari namenode sebagai pengelola metadata dari kluster, dan datanode yang menyimpan data. Inode mewakili file dan direktori pada namenode serta menyimpan atributnya seperti permission, waktu modifikasi dan akses, kuota namespace dan diskspace. Isi file dibagi menjadi blok-blok dan setiap blok tersebut direplikasi dibeberapa datanodes. Blok file disimpan pada sistem file lokal dari datanode. Namenode aktif memonitor jumlah salinan/replika blok file. Ketika ada salinan blok file yang hilang atau rusak (corrupt) pada datanode, maka namenode akan mereplikasi kembali blok file tersebut ke datanode lainnya yang berjalan baik. Namenode mengelola struktur namespace dan memetakan blok file pada datanode.
Pada komputer yang sudah terhubung dengan kluster atau disebut sebagai client, penyimpanan data dilakukan dengan mengetikkan baris perintah pada console, kemudian file akan dikirim ke kluster dan disimpan pada node-node yang tersebar dalam kluster yang bertindak sebagai datanode. Secara mendetilnya, pada saat perintah penyimpanan dieksekusi, client akan berkomunikasi dengan namenode untuk menginformasikan bahwa ada file yang akan disimpan di HDFS dan meminta lokasi datanode yang dapat diakses untuk menyimpan data tersebut. Setelah mendapatkan daftar nama dan alamat datanode yang tersedia, secara langsung client akan mengirim data ke datanode-datanode tersebut. Data yang dikirim tersebut tentu sudah dipecah menjadi blok-blok data dengan ukuran yang sesuai dengan setting. Blok-blok data ini yang kemudian disimpan oleh setiap datanode. Kemudian setelah mendapat blok data dan menyimpannya, setiap datanode akan mengirimkan laporan kepada namenode bahwa data sudah diterima dan disimpan secara normal. HDFS tidak melakukan perubahan data dan hanya melakukan penulisan saja.
Prosedur untuk membaca data serupa dengan pada saat menyimpan data, yang dilakukan dengan mengetikkan baris perintah. Pada saat perintah membaca dieksekusi, client akan berkomunikasi dengan namenode untuk memperoleh nama dan alamat datanode yang harus diakses untuk mendapatkan data yang diinginkan. Setelah informasi tersebut didapatkan, client akan secara langsung mengakses datanode yang bersangkutan untuk mengambil data. Pada akhirnya data akan ditampilkan pada client atau sesuai dengan perintah yang diberikan.
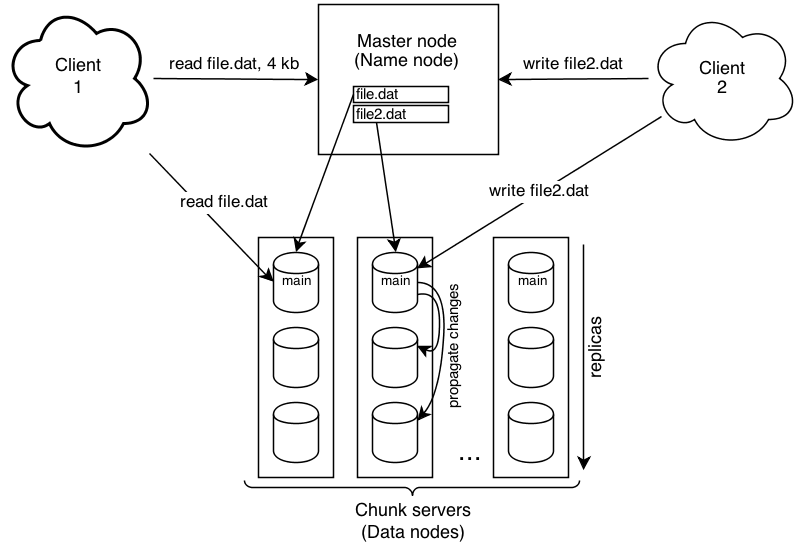
Gambar 2. Read/Write pada HDFS [1]
Penutup
HDFS adalah sebuah sistem penyimpanan data terdistribusi yang memungkinkan untuk menyimpan data berukuran sangat besar. Sistem file ini dikembangkan berdasarkan konsep dari GFS. HDFS mempunyai karakteristik sebagai sistem terdistribusi yang memiliki kapasitas berskala besar dan handal, namun demikian proses instalasinya dikenal mudah dan pengoperasiannya cukup sederhana. HDFS dapat dijalankan pada mode pseudo-distributed yang berarti dapat digunakan hanya dalam satu node saja maupun pada mode fully distributed yang berarti untuk digunakan dalam beberapa node. Saat ini semakin banyak organisasi skala menengah maupun besar yang sudah mengadopsi, seperti yang sudah dilakukan oleh Yahoo!, IBM, Facebook, Twitter, Rakuten, Amazon, dan NTT Docomo. HDFS bukan database, sehingga tidak cocok pada kondisi dimana ada tuntutan akan latency yang rendah dari proses membaca atau menulis dan terdapat banyak file yang berukuran kecil. HDFS tidak memiliki fitur pengindeksan, tidak ada akses file secara acak, dan tidak mendukung SQL. Sehingga apabila diperlukan kemampuan tambahan seperti layaknya database maka perlu menggunakan HBase.
Daftar Pustaka
[1] http://mlwiki.org/index.php/Hadoop_Distributed_File_System
[2] http://noviardisyamsuir.blogspot.co.id/2016/03/pembahasan-apa-itu-hadoop-untuk.html
[3] http://www.bmc.com/guides/hadoop-hdfs.html
[4] http://www.teknologi-bigdata.com/2013/02/hdfs-berawal-dari-google-untuk-big-data.html
[5] https://idbigdata.com/official/explandict/hdfs-hadoop-distributed-file-system/
[6] https://medium.com/skyshidigital/hadoop-distributed-file-system-c1f5c29e9e6e
[7] https://openbigdata.wordpress.com/2014/09/05/tentang-hadoop-distributed-file-system-hdfs/
[8] https://www.ibm.com/developerworks/library/wa-introhdfs/
[9] https://www.tutorialspoint.com/hadoop/hadoop_hdfs_overview.htm
Disajikan : PETERS_RICKY
Comments :