Keyword Extraction dan Keyword Suggestion pada detik.com
Penulis: David Alfa Sunarna, Kemal Anshari Elmizan, Nur Hakim Arif
Pembimbing/Editor: Dr. Amalia Zahra, S.Kom.
Detik.com (Detik) adalah sebuah portal web berita terbesar di Indonesia. Situs detik.com memiliki kolom komentar yang bertujuan supaya para pembaca bisa menyampaikan aspirasinya mengenai berita yang ada di laman tersebut. Karena website Detik sangat ramai dikunjungi oleh pembaca, kolom komentar Detik juga sangat ramai diisi oleh pembaca. Data komentar yang berjumlah banyak tersebut bisa dimanfaatkan untuk proses information retrieval dan menghasilkan keyword.
Keyword merupakan intisari atau kata kunci dari suatu berita/artikel yang dituangkan ke dalam satu atau lebih kata. Dari proses ini, Detik sudah bisa menghasilkan dan mendokumentasikan keyword secara otomatis. Keyword ini nantinya akan digunakan oleh Content Management System (CMS) milik Detik untuk menghasilkan keyword suggestion dan tagging artikel. Hal ini bertujuan untuk untuk menentukan berita terkait dari berita yang saat ini dibaca oleh pengguna. Dari sisi redaksi, keyword digunakan oleh redaktur untuk menghasilkan keyword suggestion saat membuat berita.

Ekstraksi Entitas (NER) dikenal luas sebagai algoritma untuk menghasilkan entitas dari suatu frasa atau kalimat berdasarkan nama, tempat, waktu, organisasi, dan lain sebagainya (Derczynski et al., 2015). Salah satu contoh adalah kalimat berikut:
“Menteri pendidikan memang sudah berencana menurunkan harga beras di Jakarta pada tahun 2018“
akan memproduksi entitas sebagai berikut:
“[Menteri pendidikan]orang memang sudah berencana menurunkan harga [beras]benda di [Jakarta]lokasi pada tahun [2018]waktu“
Pada kasus di Detik, satu kalimat komentar hanya akan menghasilkan satu entitas yang paling dominan. Hal ini dilakukan karena komentar biasanya tidak panjang dan kompleks.
NER memerlukan data latihan (dataset) untuk bisa memproduksi entitas secara otomatis. Detik sendiri menggunakan dataset yang sudah diperoleh dari hasil ekstraksi entitas sebelumnya untuk melatih algoritma ini secara terus-menerus. Dataset yang digunakan untuk melatih algoritma NER akan diverifikasi secara manual oleh pihak Detik agar menghasilkan output sesuai seperti yang diinginkan (supervised learning).
Tools NER yang digunakan oleh Detik adalah SpaCy (Jiang, Banchs, & Li, 2016). Tools ini dibuat dengan menggunakan bahasa Python. Output yang dapat dihasilkan di antaranya PERSON, LOC, ORG, GPE dan lain sebagainya. Dengan menggunakan SpaCy, akurasi yang didapatkan dari hasil ekstraksi sebesar 75%. Hasil ini akan diverifikasi lagi oleh internal Detik agar output ini dapat digunakan kembali sebagai training dataset untuk proses yang sama di kemudian hari.
SpaCy diimplementasikan pada Hadoop. Dengan menggunakan Hadoop sebagai data provisioning, pemrosesan teks dapat dilakukan dengan cepat serta mudah dalam pengelolaan cluster datanya. Hadoop memungkinkan Detik untuk menskalakan cluster-nya bila dibutuhkan (Nesi, Pantaleo, & Sanesi, 2015). Hadoop juga digunakan untuk menyimpan training dataset hasil verifikasi (Stokes, Kumar, …, & 2015, n.d.).
Entitas yang dihasilkan dari algoritma ini akan disimpan di dalam Detikbase. Detikbase berisi kumpulan keyword hasil ekstrasi dari entitas algoritma NER. Detikbase ini digunakan untuk melakukan tagging artikel secara otomatis ketika redaksi membuat berita. Pada Content Management System (CMS) detik.com, kolom keyword akan terisi secara otomatis setiap kali redaksi mengetik tiap kata. Kolom keyword ini dapat diubah oleh redaksi bila dianggap tidak sesuai dengan konteks materi yang dibuat. Tampilan pada CMS detik dapat dilihat pada Gambar 1 berikut ini.
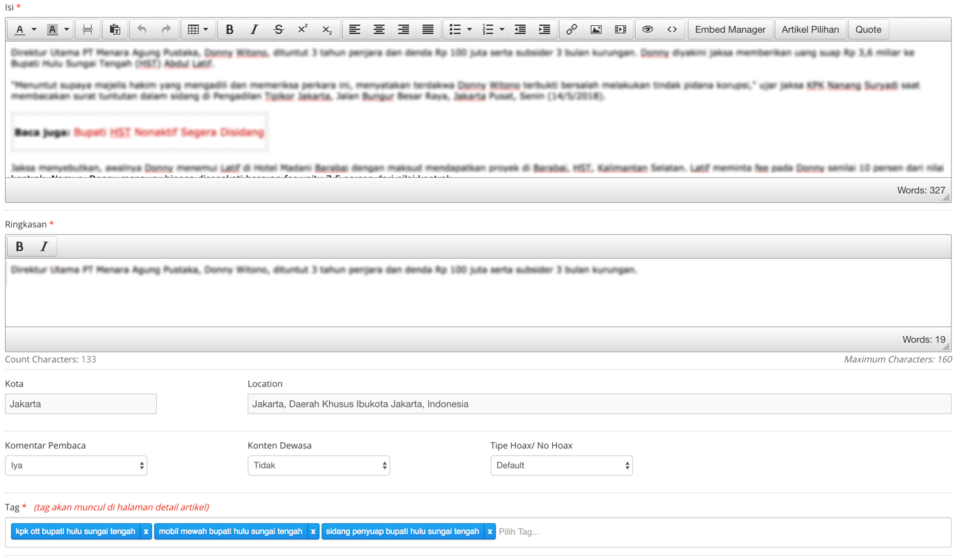
Gambar 1. Contoh Tampilan CMS Detik
REFERENSI
Derczynski, L., Maynard, D., Rizzo, G., Van Erp, M., Gorrell, G., Troncy, R., … Bontcheva, K. (2015). Analysis of named entity recognition and linking for tweets. Information Processing and Management, 51(2), 32–49. https://doi.org/10.1016/j.ipm.2014.10.006
Jiang, R., Banchs, R. E., & Li, H. (2016). Evaluating and Combining Named Entity Recognition Systems. Sixth Named Entity Workshop, 21–27. https://doi.org/10.3115/1572392.1572430
Nesi, P., Pantaleo, G., & Sanesi, G. (2015). A Distributed Framework for NLP-Based Keyword and Keyphrase Extraction From Web Pages and Documents. Pdfs.semanticscholar.org, 155–161. https://doi.org/10.18293/DMS2015-024
Stokes, C., Kumar, A., … F. C.-B. D. (Big D., & 2015, undefined. (n.d.). Scaling NLP algorithms to meet high demand. Ieeexplore.ieee.org. Retrieved from http://ieeexplore.ieee.org/abstract/document/7364095/
Comments :