Nonnegative Matrix Factorization
Nonnegative matrix factorization pertama kali dikenalkan oleh Paatero dan Tapper pada tahun 1994. Namun, berkembag menjadi popular oleh Lee dan Seung pada tahun 1999. Nonnegative matrix factorization (NMF) merupakan salah satu metode dari text mining. Tujuan dari metode NMF untuk memperkenalkan text mining dilakukan dengan teknik pengelompokan partisional yang mengindetifikasi fitur semantik dalam suatu kumpulan dokumen dan mengelompokan dokumen kedalam kluster-kluster berdasarkan fitur semantiknya. Dalam text mining, vektor merepresentasikan atau mengidentifikasi fitur semantik, seperti kumpulan kata yang menunjukan suatu topik tertentu, kemudian dikategorikan kedalam topik yang direpresentasikan oleh vektor utamanya. NMF digunakan untuk mengatur koleksi teks kedalam bentuk terstruktur atau dikelompokan secara langsung berdasarkan faktor nonnegative.
NMF berbeda dengan metode rank reduction untuk model vector space yang ada dalam text mining, misalnya principal component analysis (PCA) atau vector quantization (VQ), karena penggunaan batasan yang menghasilkan basis vector nonnegative, yang memungkinkan konsep representasi berbasis bagian . Lee dan Seung pertama kali memperkenalkan notasi part-based untuk permasalahan analisa gambar atau text mining yang menempati nonnegative subspaces dalam vector space model. Dalam model vector space standar, kumpulan dokumen S dapat diekspresikan sebagai m x n matrix V, dimana m merupakan jumlah pola dalam kamus dan n adalah jumlah dokumen dalam S. Setiap kolom Vj dari V merupakan suatu pengkodean dari satu dokumen S dan setiap masukan vij dari vektor Vj merupakan siknifikasi dari pola i sehubungan dengan semantic dari Vj, dimana i berkisar dalam pola yang ada dalam kamus. Permasalahan NMF adalah mencari perkiraan peringkat rendah V dalam beberapa matriks dengan memfaktorkan V kedalam produk (WH) dari dua matriks dimensi-reduksi W dan H. Setiap kolom W merupakan basis vektor, misalnya terdiri dari pengkodean ruang semantik atau konsep dari V dan setiap kolom H terdiri dari pengkodean kombinasi linier dari basis vektor yang mendekati kolom V yang sesuai. Dimensi dari W = m x k dan H = k x n, dimana k merupakan jumlah topik terpilih. Terkadang k dipilih lebih sedikit dari n, tetapi lebih akurat, k << min(m,n). Dalam mencari nilai k yang sesuai tergantung pada aplikasi dan juga isi dari koleksi data itu sendiri.
Pendekatan umum dalam NMF memperoleh pendekatan dari V dengan komputasi suatu pasangan (W,H) untuk meminimalisir Forbenius norm dari perbedaan V-WH. Masalah dapat dituangkan dengan V ∈ Rmxn sebagai nonnegative matriks dan W ∈ Rmxk dan H ∈ Rkxn untuk 0 < k << min(m,n).
Matriks W dan H tidak unik, biasanya H diinisiasi dari nol dan W untuk matriks yang dihasilkan secara acak dimana Wij > 0 dan estimasi awal ini ditingkatkan atau diupdate dengan menambahkan iterasi dalam algoritma. Terdapat beberapa macam teknik dalam NMF seperti multiplicative method, sparse encoding dan a hybrid method.
Berikut ini contoh pada pebelitian Suryanto Ang(2009), judul “Pengelompokan Dokumen Bahasa Indonesia Dengan Teknik Reduksi Dimensi Nonnegative Matrix Factorization Dan Random Projection”
D1: Kalangan investor di bursa saham Wall Street, New York, menantikan langkah baru yang akan diambil untuk menyelamatkan industri keuangan.
D2:Investor saham di Indonesia perlu inisiatif baru yang perlu diambil untuk menyelamatkan industri keuangan negara.
D3:Valentino Rossi mengukir hasil yang memuaskan saat melakukan tes di Sirkuit Sepang, Malaysia.
Dengan menggunakan Tf-Idf menghasilkan matriks Vmxn.
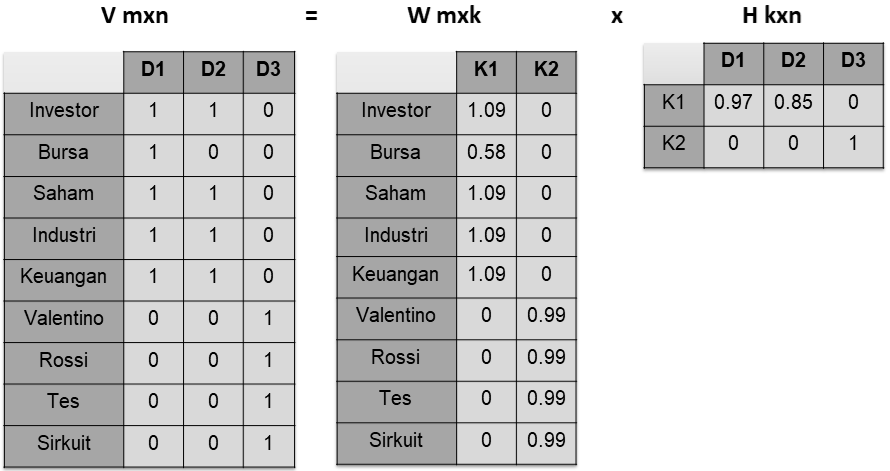
Non-Negative Matrix Factorization (NMF) memberikan non-negative matrix V untuk menghasilkan non-matrix factor W dan H seperti persamaan berikut ini.
V =WH
Pada awalnya nilai matriks W dan H bersifat acak, kemudian nilai matriks diupdate untuk mendapatkan hasil yang semakin mendekati matriks V. Matriks H diupdate dengan menggunakan rumus
H= H*(W’H)/(W’WH)+E
Matriks W diupdate dengan menggunakan rumus
W= W*VH’/ (WHH’+E)
Comments :