Review: Speaker Diarization with Enhancing Speech for the First DIHARD Challenge
Paper Review oleh Gilang Gumelar, Panca Oktavia C.S., dan Pitri Maiyani
Editor: Amalia Zahra, S.Kom., Ph.D.
Referensi: Sun, L., Du, J., Jiang, C., Zhang, X., He, S., Yin, B., & Lee, C. H. (2018, September). Speaker Diarization with Enhancing Speech for the First DIHARD Challenge. In Interspeech (pp. 2793-2797).
Pada paper referensi tersebut, peneliti melakukan perancangan sistem diarisasi pembicara untuk tantangan DIHARD 1 dengan mengintegrasikan beberapa modul penting dari speech denoising, speech activity detection (SAD), i-vector design dan scoring strategy. Tantangan DIHARD 1 sendiri merupakan tantangan untuk membuat sistem yang mampu menentukan “who spoke when” berdasarkan rekaman audio multispeaker. Dengan menggunakan long short-term memory (LSTM) based speech denoising model, dapat ditunjukkan kemampuan generalisasi yang kuat hingga realistis terhadap lingkungan yang bising dan banyak noise. Data speech yang telah ditingkatkan dapat meningkatkan kinerja untuk SAD berikutnya, segmentasi dan pengelompokan. Penelitian dilakukan dengan menggunakan dataset yang besar, yakni berasal dari 30.000 orang. Deteksi aktivitas ucapan berbasis deep neural network (DNN) diuji coba dengan data yang dikumpulkan secara realistis. Selanjutnya dibuat ekstraksi i-vector untuk representasi speaker yang dikombinasikan dengan model penilaian PLDA. Kemudian diusulkan melakukan ekstraksi convolutional neural network (CNN) berbasis i-vector dan membuat fusion dengan PLDA score secara tradisional. Terakhir dilakukan evaluasi performa dari Track 1 dan Track 2, sebagaimana tergambar pada arsitektur berikut:
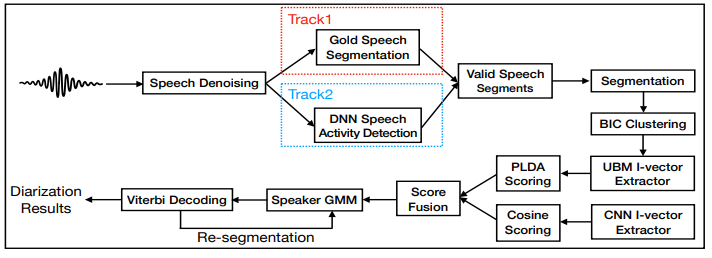
Berdasarkan proses arsitektur sistem dengan skor perpaduan berbagai macam teknik ini, sistem yang dihasilkan oleh peneliti dapat menghasilkan tingkat kesalahan diarisasi (DER) sebesar 24,56% dan 36,05% pada set evaluasi Track1 dan Track2. Pertama, dibangun diarisasi speaker dasar pada UBM i-vector extractor dan model PLDA. Keduanya dilatih berdasarkan data VoxCeleb asli. Di Track1, hanya digunakan segmentasi ucapan asli, sedangkan Track2 menggunakan output dari SAD berbasis DNN. DER pada himpunan data pengembangan bisa mendapatkan keuntungan langsung dari pidato yang ditolak sebesar 20,26% hingga 19,68% di Track1. Sistem yang dibangun tidak dapat menangani segmen ucapan yang tumpang tindih. Artinya, semua segmen yang tumpang tindih akan didistribusikan hanya ke satu speaker, yang menghasilkan kesalahan tak terelakkan di kedua Trek. Secara khusus, Nona adalah 8,5% di Track1, sedangkan False Acceptance (FA) bernilai 0 dengan segmentasi asli. Di Track2, ucapan yang ditolak dapat mengurangi persentase secara signifikan dari Miss dan FA, karena penghapusan gangguan lingkungan. Selain itu, segmen ucapan yang valid tidak terlalu membingungkan, dalam hal pengurangan SpkrErr. Selanjutnya dengan melatih kembali ekstraktor i-vector dan model PLDA menggunakan denoised data pelatihan, peningkatan tambahan dapat diamati, baik Track1 dan Track2 seperti yang ditunjukkan di baris ketiga di setiap track.
Untuk penggunaan gabungan UBM i-vector dan CNN i-vector, dilakukan scoring fusion antara skor PLDA UBM i-vector dan skor cosinus CNN i-vector. Dibandingkan dengan penilaian PLDA tunggal, fusi metode memperoleh pengurangan SpkrErr relatif sebesar 19,2% di Track1 dan 9,2% di Track2. Dengan demikian, algoritma yang dirancang secara baik dapat membantu mendeteksi diarisasi segmen pidato dengan benar. Selanjutnya rancangan yang berbeda dari i-vector dapat membantu melengkapinya.
Adapun untuk penelitian selanjutnya, saran dari kami adalah dengan memasukkan metode deteksi speech yang tumpang tindih, sehingga dapat dilakukan pemisahan terlebih dahulu sebelum dilakukan proses diarisasi.
Comments :