Paper Review: Performance Analysis of ANN and Naïve Bayes Classification Algorithm for Data Classification
Paper Review oleh Ivan Fangnata Santoso, Jasen Wanardi Kusno, Giovinno Bryan William
Editor: Amalia Zahra, S.Kom., Ph.D.
Referensi: Saritas, M. M., & Yasar, A. (2019). Performance analysis of ANN and Naive Bayes classification algorithm for data classification. International Journal of Intelligent Systems and Applications in Engineering, 7(2), 88-91.
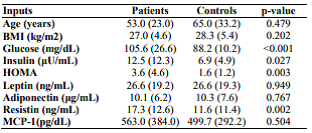
Penelitian ini berfokus pada pendeteksian kanker payudara menggunakan fitur-fitur berikut: umur (tahun), BMI (kg/m2), glukosa (mg/dL), insulin (μU/mL), HOMA, leptin (ng/mL), adiponectin (μg/mL), resistin (ng/mL), dan MCP-1(pg/dL). Fitur-fitur tersebut didapatkan dari pasien yang didiagnosa mengidap kanker payudara berdasarkan hasil mammography yang positif serta hasil histologi. Semua data pasien yang digunakan merupakan data naive, di mana setiap data pasien diambil sebelum dilakukan tindakan penyembuhan atau penanganan medis apapun. Informasi statistik dari fitur yang digunakan pada penelitian ini ditampilkan pada Tabel 1.
Tabel 1. Informasi Statistik Fitur-fitur Dataset Pasien
Klasifikasi dilakukan dengan Artificial Neural Network (ANN). Arsitektur ANN yang paling optimum diperoleh dari sejumlah iterasi proses pelatihan data, yakni terdiri dari satu input layer dengan 10 nodes, 10 hidden layers, dan satu output layer dengan satu node, seperti terlihat pada Gambar 1.
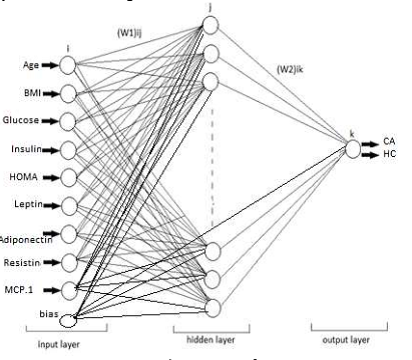
Gambar 1. Arsitektur ANN yang Digunakan
Adapun parameter yang digunakan dapat dilihat pada Tabel 2.
Tabel 2. Parameter Arsitektur ANN yang Digunakan

Dataset yang digunakan terdiri dari 64 data pasien dengan diagnosa kanker payudara dan 52 data orang yang sehat. Dataset dibagi menjadi 29 samples untuk testing, 12 samples untuk validasi, dan sisanya untuk training. Pembagian ini dilakukan secara acak. Gambar 2 menampilkan kinerja model menggunakan data training, test, dan validasi.
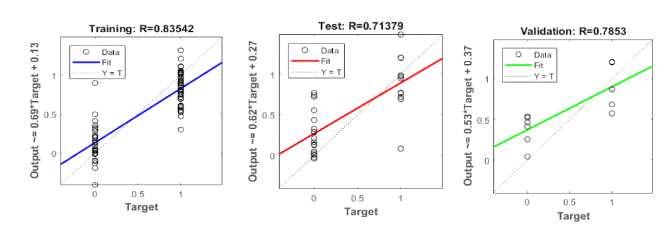
Gambar 2. Kinerja Model Menggunakan Data Training, Test, dan Validasi
Berdasarkan hasil penelitian, diketahui bahwa terdapat penurunan nilai recall antara training dengan validasi maupun testing. Perbedaan akurasi antara training dan testing melebihi 10%, menunjukkan bahwa model masih cenderung fitting ke data training. Selain itu, penelitian menggunakan 64 sample data pasien dan 52 sample data orang sehat, mengasumsikan bahwa perbandingan kasus kanker payudara dianggap sebagai kasus yang memiliki data seimbang.