Word Embedding dengan FastText
Word embedding atau word vector representation merupakan jenis teknik representasi kata yang memungkinkan kata-kata dengan makna yang sama memiliki representasi sama. Word embedding memiliki peran penting dalam membangun vektor kata berkelanjutan berdasarkan konteks dalam korpus besar. Word embedding menangkap informasi semantik dan kata sintaksis, yang dapat digunakan untuk mengukur kemiripan kata, yang mana banyak digunakan dalam berbagai proses IR, dan NLP .
FastText adalah library yang dikembangkan oleh Facebook yang dapat digunakan untuk word embedding. FastText merupakan pengembangan dari library Word2Vec yang telah lebih lama dikenal sebagai metode untuk proses word embedding.
Berbeda dari Word2Vec, FastText tidak memakai hanya satu kata secara utuh untuk diproses, tapi FastText menggunakan n-gram. Contoh implementasi n-gram pada kata “pintar” dengan trigram (n=3) berupa “pin”, “int”, “nta”, “tar”. Kelebihan FastText adalah waktu proses yang relatif cepat. Berbeda dengan Word2Vec, FastText dapat menangani kata yang tidak pernah muncul di kamus (vocabulary), yang mana dalam Word2Vec hal seperti ini akan menghasilkan error
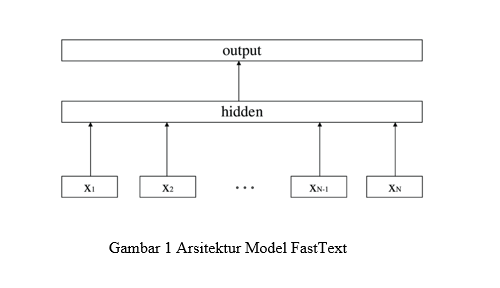
FastText menyediakan pilihan untuk menggunakan salah satu dari dua algoritma utama FastText, yakni Continous Bag of Words (CBOW) dan Skip-gram. Kedua algoritma tersebut menggunakan neural network untuk mendapatkan model terbaik yang mampu merepresentasikan sebuah kata dalam vektor
Gambar 1 Arsitektur Model FastText
Disadur dari :
Suminar Ariwibowo, Abba Suganda Girsangao, Klasifikasi Teks Hate-Speech Menggunakan Long Short-Term Memory (LSTM), Tesis, Universitas Bina Nusantara, Jakarta. 2021