Optical Character Recognition (OCR)
Penulis: Michael Reynaldo Phangtriastu
Dosen Pembimbing: Gede Putra Kusuma, PhD
1. Pendahuluan
Optical character recognition (OCR) adalah proses konversi gambar huruf menjadi karakter ASCII yang dikenali oleh komputer. Gambar huruf yang dimaksud dapat berupa hasil scan dokumen, hasil print-screen halaman web, hasil foto, dan lain-lain (Mohammad, Anarase, Shingote, & Ghanwat, 2014).
Salah satu kebutuhan mengapa perlu konversi gambar huruf menjadi karakter ASCII adalah karakter ASCII memiliki kapasitas penyimpanan yang lebih kecil. Contohnya, suatu paragraf di-printscreen dan disimpan dalam format png. Paragraf tersebut juga di-copy dan disimpan dalam format .txt. Untuk file gambar, memiliki size 42KB, sedangkan untuk file teks, memiliki size 1KB. Dari sini bisa terlihat bahwa file gambar akan selalu relatif lebih besar ketimbang menyimpan langsung teks ASCII-nya saja.
Gambar 1.1 Hasil print screen suatu paragraf dari Wikipedia
![]()
Gambar 1.2 Ukuran dari gambar print screen paragraf

Gambar 1.3 Paragraf dari Wikipedia yang disimpan dalam file teks
![]()
Gambar 1.4 Ukuran dari file teks paragraf
OCR adalah sistem yang sudah lama dikembangkan. Tahun 1914, Emanuel Goldberg telah mulai membuat sistem OCR yang berfungsi untuk telegram dan alat baca untuk orang tunanetra. Sistem OCR terus dikembangkan hingga kini sehingga dapat menghasilkan akurasi yang lebih baik bahkan dalam situasi-situasi yang dimana karakter sulit untuk dikenali.
Pengaplikasian OCR sendiri memungkinkan komputer untuk melakukan proses lebih lanjut, contohnya translasi ke bahasa asing, pencarian, sistem baca otomatis untuk orang tunanetra, input data, pengenalan karakter seperti plat nomor, pengetesan CAPTCHA, atau masalah teks lainnya.
Hasil dari OCR bisa disimpan langsung dalam bentuk ASCII, namun untuk kasus tertentu, butuh disimpan layout-nya. Yang dimaksud dengan layout adalah posisi paragraf, margin, dan lainnya, sehingga sama persis dengan gambar yang diolah. Layout butuh disimpan contohnya dalam kasus konversi hasil scan buku ke dalam file .doc, tentunya posisi paragraf dan lainnya perlu disamakan. Untuk menyimpan layout, dapat disimpan menggunakan suatu format XML (Extended Markup Language) bernama ALTO (Analyzed Layout and Text Object) yang dokumentasinya dapat ditemukan di http://www.loc.gov/standards/alto/.
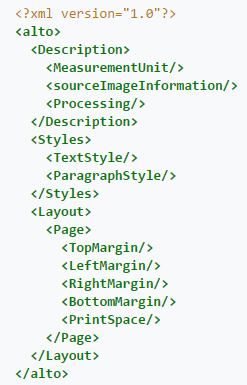
Gambar 1.5 Tag – tag dari format ALTO
2. Tinjauan Pustaka
- Optical Character Recognition (OCR)
Character Recognition bertugas untuk mengenali tulisan didalam mengenali karakter tulisan dalam gambar dan merubahnya kedalam American Standad Code for Information Interchange (ASCII) atau bahasa mesin lainnya yang setara dan dapat diedit. Terdapat dua macam Character Recognition, antara lain: Offline dan Online Character Recognition (Rao, Sasrty, Chakracarthy, & Kalyanchakravarthi, 2016).
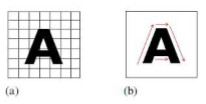
Gambar 2.1 (a) Offline Character Recognition (b) Online Character Recognition
Character recognition juga diklasifikasikan kedalam dua tipe berdasarkan metode tulisannya, antara lain: Optical Character Recognition (OCR) dan Handwritten Character Recognition (HCR). Dimana akurasi pada HCR biasanya masih lebih rendah dikarnakan besarnya perbedaan bentuk dan tipe tulisan. Perbedaan karakter dalam Bahasa juga berpengaruh besar, contohnya: tulisan kanji mandarin, jepang, dan lainnya (Rao, Sasrty, Chakracarthy, & Kalyanchakravarthi, 2016).
Dalam proses OCR berikut ini gambaran sistem yang akan dilakukan (Mohammad, Anarase, Shingote, & Ghanwat, 2014):
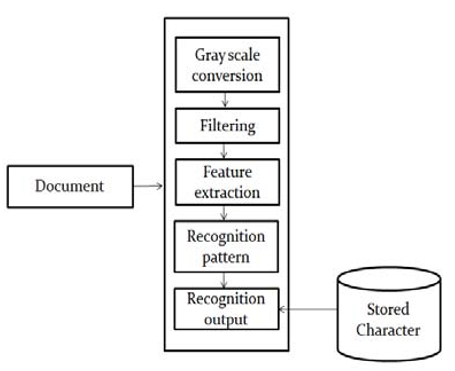
Gambar 2.2 System Block Diagram
Grayscale pada gambar bermaksud untuk memastikan intensitas setiap pixel, untuk meningkatkan akurasi data yang diinput. Dalam prosesnya grayscale merubah warna dasar yang sebelumnya merupakan RGB model, menjadi model grayscale menggunakan fungsi berikut (Mohammad, Anarase, Shingote, & Ghanwat, 2014):
![]()

Gambar 2.3 Hasil operasi black –white dan grayscale
Feature Extraction adalah proses untuk mendapatkan informasi terhadap object ataupun kelompok object untuk memfasilitasi proses klasifikasi. Diantaranya yang dilakukan adalah: memotong data gambar per-karakter yang ditemukan, menormalisasi ukuran pixel, menerjemahkan data pixel kedalam binary (Mohammad, Anarase, Shingote, & Ghanwat, 2014).
Pattern Recognition dilakukan berdasarkan format data binary yang ada, kemudian membagi binary kedalam 5 track, dimana setiap track dibagi lagi menjadi 8 sector. Keterkaitan matrix track dan sector berguna untuk mendeteksi sekelompok pixel di setiap bagian (Mohammad, Anarase, Shingote, & Ghanwat, 2014). Pada masing-masing bagian, jumlah angka 1 dihitung kemudian output recognition dapat dilakukan dengan menggunakan metode klasifikasi tertentu, misalnya ANN atau SVM.
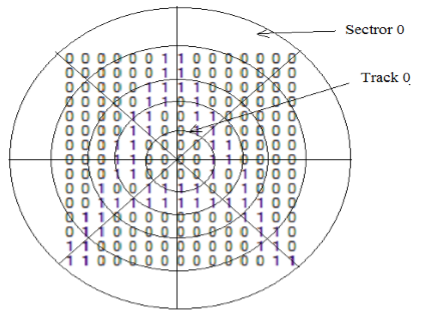
Gambar 2.4 Pembagian kedalam track dan sector
- Offline dan Online Character Recognition
Offline character recognition system men-generate dokumen terlebih dahulu, melakukan digitalisasi, dan menyimpannya kedalam computer, sebelum memprosesnya. Dimana untuk online character recognition system, character langsung di proses selama dalam pembuatan. Faktor eksternal seperti kecepatan menulis berpengaruh pada kasus offline system. Offline ataupun Online system dapat diterapkan untuk optical maupun handwritten characters recognition (Rao, Sasrty, Chakracarthy, & Kalyanchakravarthi, 2016).
- Template Matching
Template matching dalam OCR adalah paten yang dimiliki oleh Hin-Leong Tan (Tan, 1991). Dalam template matching, pixel masing-masing gambar dicocokkan dengan template yang sudah disediakan, karakter yang memiliki kecocokkan tertinggi dianggap sebagai karakternya.
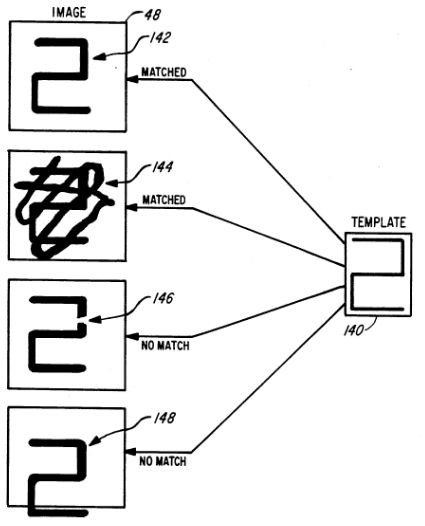
Gambar 2.5 Simulasi template matching
- Zoning
Zoning adalah teknik dimana gambar suatu karakter dibagi dalam beberapa area, kemudian dihitung densitasnya dengan cara jumlah pixel hitam dibagi dengan total keseluruhan pixel di zona tersebut. Dari teknik zoning ini, dihasilkan fitur dengan ukuran sebesar area yang telah ditentukan (M.O, Chacko, & Dhanya, 2015).
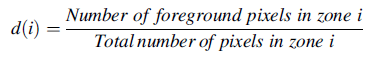
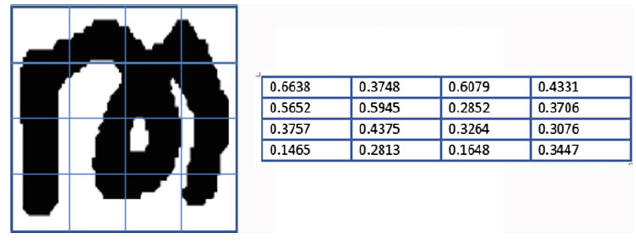
Gambar 2.6 Simulasi zoning dengan ukuran area 4 x 4
- Projection Profile
Projection profile adalah menambahkan jumlah pixel hitam per baris dan per kolom (M.O, Chacko, & Dhanya, 2015). Sehingga bila ukuran gambar adalah 256 x 256, dihasilkan 512 buah fitur. Karena jumlah fitur bisa sangat banyak tergantung dari ukuran gambar, disarankan agar dimensi hasil projection profile diperkecil misalnya dengan menggunakan teknik PCA.
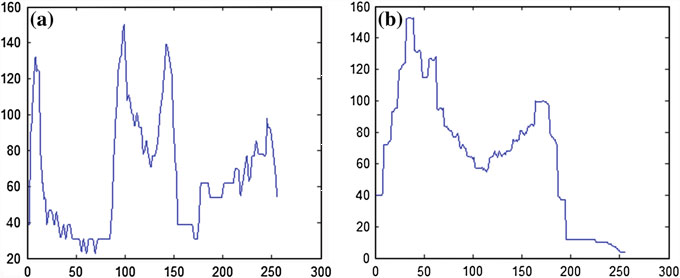
Gambar 2.7 Contoh hasil projection profile dalam bentuk histogram
- Chain Code Feature
Chain code adalah suatu cara untuk mendapatkan kontur dari suatu objek (M.O, Chacko, & Dhanya, 2015).
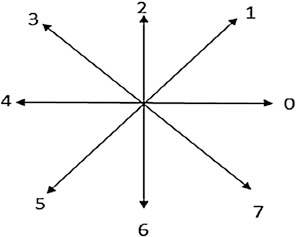
Gambar 2.8 Kode arah chain code dalam metode Freeman
Algoritma chain code dilakukan dengan cara memulai dari titik (pixel hitam) tertentu dalam gambar, kemudian titik dipindahkan ke tetangganya dan dicatat arah geraknya berdasarkan kode arahnya. Titik terus dipindahkan sampai titik akhir dari kontur.
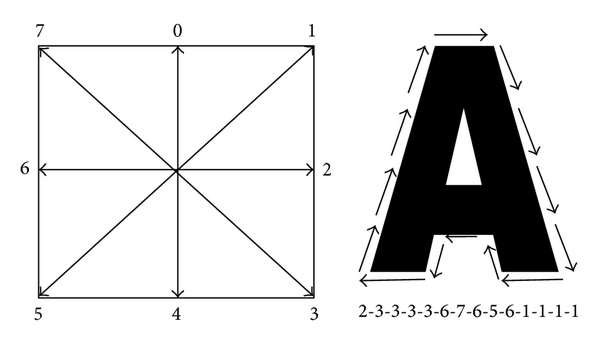
Gambar 2.8 Contoh implementasi chain code

Gambar 2.9 Contoh hasil chain code yang dibuat dalam bentuk histogram
- Histogram of Oriented Gradient (HOG)
Dalam HOG, gambar dibagi dalam beberapa bagian, kemudian dari masing-masing bagian, ditentukan arah gradientnya yang didapatkan dari normalisasi masing-masing gradient pixel dalam bagian gambar.
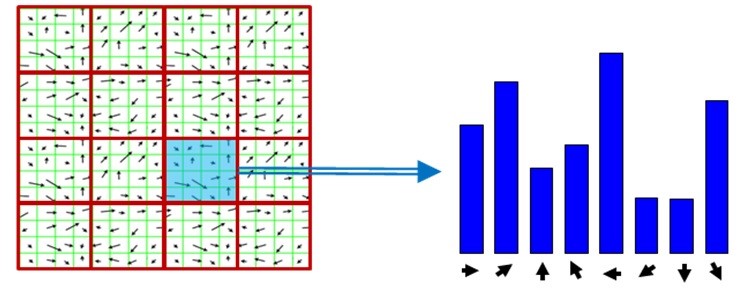
Gambar 2.10 Contoh hasil HOG
3. Pembahasan dan Hasil
Untuk melakukan OCR, sebelumnya gambar dipisahkan terlebih dahulu sehingga didapatkan karakternya. Pemisahan dilakukan per baris, kemudian dari masing-masing barisnya, dipisahkan karakternya (Mohammad, Anarase, Shingote, & Ghanwat, 2014).

Gambar 3.1 Pemisahan baris

Gambar 3.2 Pemisahan karakter
Setelah gambar berhasil dipisahkan menjadi satu bagian yang dianggap sebagai satu karakter, bagian gambar tersebut di-crop dan di-scale ukurannya menjadi ukuran tertentu.
Gambar 3.3 Crop dan scale karakter
Kemudian gambar dibuat menjadi hitam – putih menggunakan teknik grayscale kemudian di-threshold, kemudian akan diproses menggunakan angka binernya.
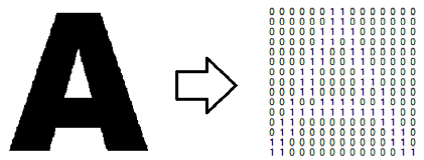
Gambar 3.4 Karakter diubah menjadi matriks biner.
Dari hasil implementasi template matching yang telah dilakukan oleh Nadeem dan Rizvi (Nadeem & Rizvi):
Sedangkan (Mohammad, Anarase, Shingote, & Ghanwat, 2014) menyatakan bahwa hasil yang mereka peroleh mencapai 100% untuk karakter yang template font-nya telah dikenali. Namun akurasi berkurang drastis untuk deteksi HCR.
Dalam penelitiannya, (M.O, Chacko, & Dhanya, 2015) mengimplementasi Zoning, Projection Profile, Chaincode, dan HOG pada HCR, dengan hasil:
4. Kesimpulan dan Saran
Dari hasil – hasil yang telah dipaparkan dalam penelitian – penelitan sebelumnya, dapat disimpulkan bahwa untuk OCR dengan karakter yang tercetak, akurasi sudah baik. Yang perlu dikembangkan lagi adalah karakter tulis tangan (HCR). Untuk meningkatkan akurasi, bisa dilakukan metode preprocessing pada gambar, atau menggunakan fitur lainnya. Bisa juga menggabungkan beberapa fitur atau metode sekaligus menggunakan teknik ensemble.
Selain itu, untuk meningkatkan akurasi bisa juga melakukan teknik post-processing yang dimana kata dicek ke dalam kamus, bila tidak ada, kata disesuaikan menjadi kata terdekat. Untuk memaksa agar akurasi menjadi sangat baik, bila memungkinkan bisa menggunakan font yang telah dispesifikasikan, seperti OCR-A, OCR-B, atau MICR. Font – font ini adalah font yang mudah dibedakan antar karakternya sehingga tidak terjadi klasifikasi karakter yang salah.
Gambar 4.1 OCR-A, OCR-B, dan MICR
Daftar Pustaka
M.O, A. M., Chacko, & Dhanya, P. (2015). A Comparative Study of Different Feature Extraction Techniques for Offline Malayalam Character Recognition.
Mohammad, F., Anarase, J., Shingote, M., & Ghanwat, P. (2014). Optical Character Recognition Implementation Using Pattern Matching. International Journal of Computer Science and Information Technologies, 2088-2090.
Nadeem, D., & Rizvi, S. (n.d.). Character Recognition using Template Matching.
Rao, V., Sasrty, A., Chakracarthy, A., & Kalyanchakravarthi, P. (2016). Optical Character Recognition Technique Algorithms. Journal of Theoretical and Applied Information Technology, 83(2), 275-282.
Tan, H.-L. (1991). Hybrid feature-based and template matching optical character recognition system.
Comments :